
假设检验背后那点事儿
统计推断中的假设检验,是数据分析最常用的技术之一。理论上,但凡涉及抽样的问题,都需要进行假设检验。包括方差分析、回归分析和相关分析,这些字面上看起来与假设检验无关的分析技术,实际上也是以假设检验为核心的。当前广泛使用的假设检验基本源自Neyman-Pearson的理论。NP理论汲取了卡方拟合优度检验(K. Pearson)和显著性检验(R.A. Fisher)思想的精华,完备了显著性检验的数学基础。
假设检验中使用频率最高的要数$t$检验。$t$分布中$t$统计量的诞生,主要是为了解决小样本条件下样本平均数的概率分布问题。当总体方差未知,且样本容量较小时,用样本方差代替总体方差构建形似$z$统计量的新统计量$t$,它不再服从标准正态分布。实践中,方差未知和小样本又是最常见的情形,$t$检验在假设检验中的地位可见一斑。下面我们构建一个适用$t$检验的场景,来谈谈假设检验背后的基本逻辑思想。
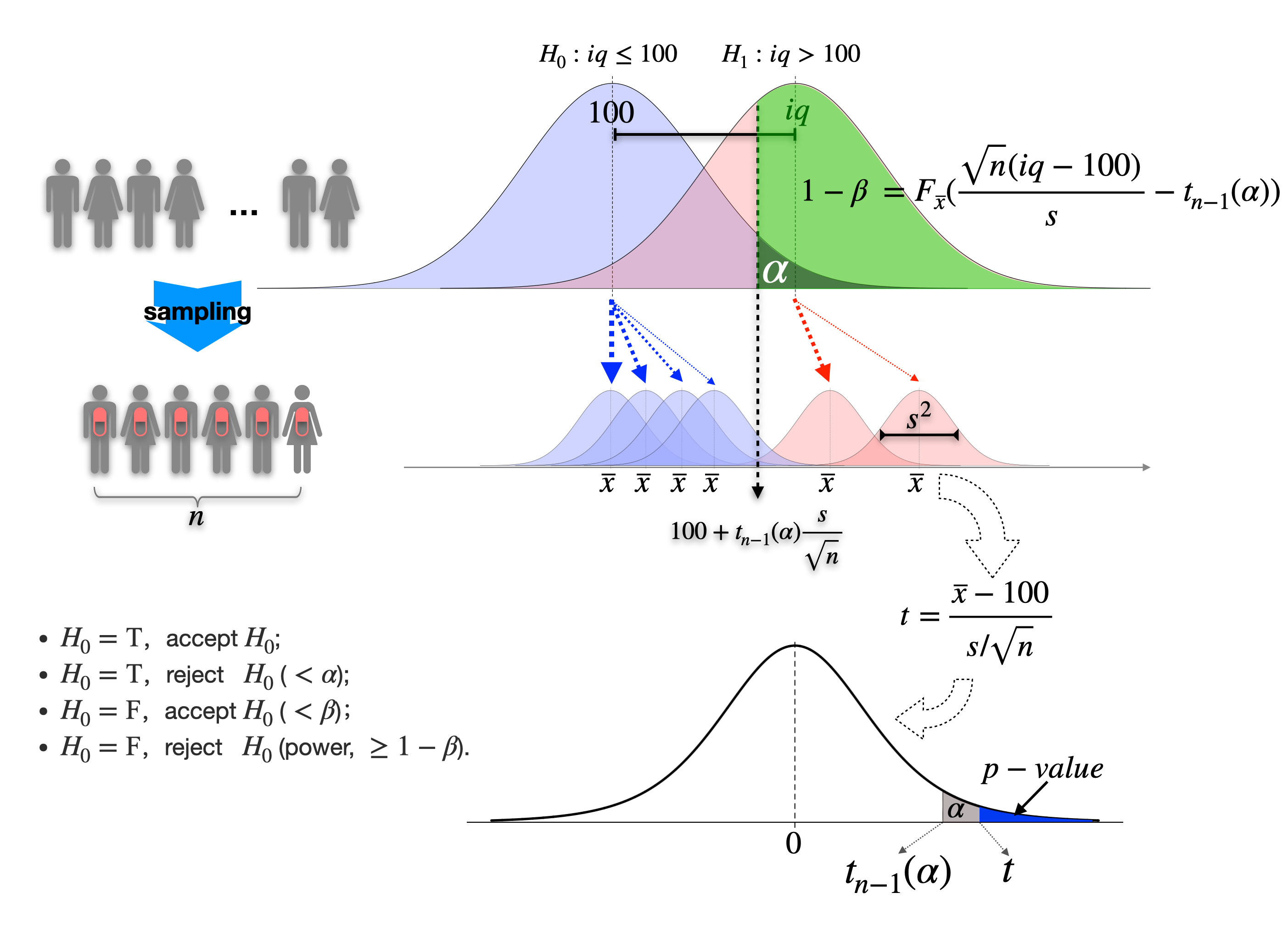
假设某科研团队研发了一种神奇的药物,声称可以提升人类智商,现在需要测试药物是否真的有效。这个问题的答案只有两种对立的结果:药物无效和药物有效,不存在模棱两可的效果,也不存在对部分人群有效或无效的选择性差异。首先,将这两种结果转变成“假设”的形式,对应无效回答的称之为零假设,用$H_0$表示,对应有效回答的称之为备择假设,用$H_1$表示。NP理论设立对立的两种假设,有别于R.A. Fisher的显著性检验思想,后者仅针对问题提出一个假设。有了对立的假设,还需要找到一个与假设直接相关的量,并将其取值的不同范围与假设是否成立联系起来。因为需要检验的是这个药物是否会提高智商,而恰巧智商是可以定量描述的,所以与假设联系起来的量自然就是智商的IQ值。接下来,我们就可以动手收集数据了。出于种种原因有一小撮志愿者愿意参与药物试验,服药一段时间后测试了他们的IQ值。最后根据样本数据,进行统计计算,作出零假设是否成立的判断。这里我们一笔带过了最核心的环节,即进行统计计算,究竟如何计算?又为何那样计算呢?下面我们展开来详细说明。
在开始之前,有件事情需要先交代一下。实践中对于该检验问题,合理的设计应该是在受试者服药前后的分别获得IQ值数据,然后在两者之间进行比较。因为志愿者在试药前IQ值的分布,一般不太容易与人类IQ总体分布向吻合。有可能志愿者的IQ样本分布的中心(均值)相对于IQ总体分布的中心是向左移的,也可能是向右移的。造成这种偏差的主要原因是,志愿者并不是从人类总体中随机抽取的,而自愿报名的。样本的组成很大程度上反应了志愿者的主观意愿。这里为了简化问题,我们作单样本检验,即将志愿者的样本分布视为从人类IQ总体分布中随机抽取的。下面我们正式开始讨论NP理论是如何思考假设检验问题的。
用概率论的方式理解,IQ值是一个随机变量。作为总体,全人类的IQ有一个总体分布。这一小撮志愿者在服药后的IQ值,作为样本,也有一个样本分布。假设全人类IQ的总体分布有均值$100$,样本有均值$\overline{x}$。这里我们约定该药物对受试者的IQ没有副作用,也就是说该药物不会降低原本的IQ值。因此,用定量的方式描述药物的效果,即$\overline{x}-100$。如果这个IQ差值很大,比如$\overline{x}-100 = 100$,那么剩下的几乎就只有欢呼雀跃了。可是如果差值是$5$和$8$之类的结果呢?你是不是会犹豫呢?还有如果差值是负值呢?因为样本是随机抽的,所以用药前的IQ样本均值可能小于$100$,此时如果药物无效,且智商测试没有偏差的话,差值就会为负。综合来说,当$\overline{x}$比$100$大的越多,我们对药物无效的零假设信心越不足;当$\overline{x}$与$100$差不多甚至小于$100$时,我们对药物无效的零假设信心越足。现在就可以将两种假设与IQ值的取值范围联系起来了:$H_0: iq \leq 100$和$H_1: iq > 100$($iq$表示用药后$\overline{x}$的具体取值)。这里再引入NP理论的第二对概念:接受域和拒绝域。当$iq \leq 100$时是要接受$H_0$的,所以$iq !\leq! 100$就称为接受域,相应的$iq > 100$称为拒绝域。
接受域和拒绝域虽然可以这样泾渭分明的定义,但是显然不能根据这样的标准来判断假设是否成立。正如上面所说的,当差值很大时($iq$在拒绝域内)我们对$H_1$成立的信心就会增强;而当差值较小时,虽然也在拒绝域内,但这时对$H_1$成立的信心会大大降低。面对不同差值信心发生变化,这背后隐含的逻辑是非常自然的。但还是要追问下去,为什么较小的差值会让我们对拒绝$H_0$接受$H_1$的信心不足?这个问题直接关系到假设检验的核心思想。假如药物确实是无效的,那么所得到的样本数据,就相当于从人类IQ的总体中随机抽取了一小撮。现在让我们聚焦在这一小撮受试者的IQ均值$\overline{x}$上,$\overline{x}$可能小于等于$100$,也可能会大于$100$。所以$\overline{x}$的取值落在拒绝域里,$H_0$也可能成立。但是随机抽样的原理告诉我们,离$100$很近的可能性要大于远离$100$的可能性。而且,随着离$100$的距离越远,可能性越低,甚至低到我们不在相信这组样本是从均值为$100$的正态总体中抽取的,换句话说,对于观察到的较大的差值,我们开始相信这个$\overline{x}$更可能是来自一个比$100$更大均值的总体。这就是面对差值$100$时对$H_1$信心满满,而差值$5$会让我们信心不足的原因。
仅仅理解这一点是不够的,接下来我们必须用定量的方法来衡量对$H_0$成立的“信心”。而衡量“信心”的最好方法就是计算概率。必须强调,这里所谓的“信心”指的是“认为药物无效”的信心。前面已经说到如果样本是从IQ总体中随机抽取的,也就是“认为药物无效”,那么$\overline{x}$落在总体均值$100$附近的概率概率最高,所以用概率描述“认为药物无效”的信心,就相当于计算$\overline{x}$的概率。那么,$\overline{x}$的概率该如何计算呢?一种方法是从总体中再随机地多次重复抽取样本,每抽取一组就计算一个$\overline{x}$,当重复次数足够多时就可以近似地描述$\overline{x}$的概率分布。然而这种方法多数情况下是不现实的,比如对总体的信息知之甚少,而需要通过重复试验获得样本数据的时候,这种方法的成本是相当大的。第二种方法,就是从理论上推导出$\overline{x}$的概率分布,或者推导出$\overline{x}$的函数的概率分布。而且所得的概率分布没有未知参数,也就是说可以直接计算相关概率的。服从正态分布的随机变量经过标准化后的随机变量,即$\frac{x - \mu}{\sigma}$,是服从标准正态分布的。利用同样的思想,我们对$\overline{x}$构建类似的统计量$\frac{\overline{x} - \mu}{s / \sqrt{n}}$,其中分母部分是$\overline{x}$的标准差,分子部分的$\mu$是$\overline{x}$的均值或数学期望。因为前面关于$\overline{x}$概率的推理是以“药物无效”为前提的,所以$\mu = 100$。$\frac{\overline{x} - \mu}{s / \sqrt{n}}$与$\frac{x - \mu}{\sigma}$虽然形似,但它们的概率分布不同,$\frac{\overline{x} - \mu}{s / \sqrt{n}}$服从$t$分布,所以通常之为$t$统计量。显然第二种方法更好,但如果随机变量的概率分布很难获得解析的数学表达式,同时通过计算机模拟可以实现从某总体中随机抽样时,第一种方法也是可以有效解决问题的。
有了$\overline{x}$概率的计算方法,并用它来衡量“认为药物无效”的信心,接下里就要有一个标准来衡量当这种信心低到什么程度时就该放弃“药物无效”的判断了。NP理论说,约定一个所谓显著性水平$\alpha$,当$\overline{x}$的概率低于$\alpha$时就可以放弃“药物无效”的判断。也就是说,$\overline{x}$从$100$附近的高概率,沿数轴向右增大时概率越来越小,当越过一个临界值$C$时(此时$\overline{x}$取到比当前值以及比当前值还大的值的概率等于$\alpha$,$P(\overline{x} !\geq! C) = \alpha$)就要放弃“药物无效”的判断。通过$t=\frac{\overline{x} - 100}{s / \sqrt{n}}$概率分布的上$\alpha$分位数$t_{n-1}(\alpha)$可以确定这个临界值$C = 100+t_{n-1}(\alpha)\frac{s}{\sqrt{n}}$。具体的计算过程是这样的:
$$ \begin{aligned} P(\overline{x} !\geq! C) &= \alpha\ 1 - P(\overline{x} < C) &= \alpha\ P(\overline{x} < C) &= 1-\alpha\ P(\frac{\overline{x} - 100}{s / \sqrt{n}} < \frac{C - 100}{s / \sqrt{n}}) &= 1-\alpha \ F_{\overline{x}}(\frac{C - 100}{s / \sqrt{n}}) &= 1-\alpha \end{aligned} $$
其中$F_{\overline{x}}$为$t$分布的累积分布函数,根据上$\alpha$分位数的定义,所以有 $$ \begin{aligned} \frac{C - 100}{s / \sqrt{n}} &= t_{n-1}(\alpha)\ C &= 100 + \frac{\sqrt{n}}{s} t_{n-1}(\alpha) \end{aligned} $$ 这里特别需要注意的是,构建$t$统计量时,我们将$\overline{x}$的均值定为$100$,其意义在于假定了$H_0$是成立的。现在终于可以做出判断了:只要$\overline{x} > 100+t_{n-1}(\alpha)\frac{s}{\sqrt{n}}$就可以拒绝$H_0$接受$H_1$,也就是认为“药物有效”,反之则认为现有数据不足以否定“药物无效”,应该接受$H_0$。这种判断方法,在数理统计学中,就称为一个”检验“。”检验“一词有动词和名词两种含义。动词含义指的是判断全过程的操作,而名词含义指的是判断的标准,关键点就在检验临界值$C$上。在名词意义上,一个“检验“就是一个函数,这个函数表示的是检验统计量(这里就是$\overline{x}$)到判断结果的映射关系。既然检验是一个函数,不如就用一个符号$\psi$。所以$\psi: $当$\overline{x} !\leq! C$接受$H_0$,否则拒绝$H_0$。
判断已经完成,但假设检验的任务还不算结束。现在思考一下,依据上述推理做出的判断有没有可能出错呢?假如判断是“药物有效”,也就是否定了$H_0$。虽然$\overline{x}$取到当前极端值的概率小于$\alpha$,但小概率不代表不会发生。反过来假如判断是“药物无效”,也就是$\overline{x}$取到当前值的概率大于$\alpha$,尤其是比$\alpha$大的不多时,样本来自于比$100$大的总体的可能也是有的,甚至还不小。总结一下,第一种情况就是零假设为真时被拒绝,第二种情况是零假设为假时被接受。NP理论分别称两种情况为第一类错误和第二类错误。事实上只要做出判断就有可能犯错,所以只要将犯错的可能性控制在合理的范围内即可。对于第一类错误,它发生的概率是已经被控制在$\alpha$之内了,所以只要做出否定$H_0$的判断,犯第一类错误的概率都会在$\alpha$以下。对于第二类错误,要控制它在较低的水平之内就比较困难和复杂了。为了讲清楚第二类错误的控制问题,还需要引入NP理论中又一个重要的概念——功效(Power)。
功效指的是当使用检验$\psi$时$H_0$被拒绝的概率,我们用$\rho_{\psi}$表示。在检验神药的场景中,$\rho_{\psi} = P(\overline{x} > C)$。那么用检验$\psi$接受$H_0$的概率等于$P(\overline{x} !\leq! C) = 1-\rho_{\psi}$。当$H_0$为真时,如果$\overline{x} > C$就犯了第一类错误,因此这时我们要将$\rho_{\psi}$约束在$\alpha$水平之下。当$H_0$为假时,如果$\overline{x} !\leq! C$就犯了第二类错误,因此这时我们要$1-\rho_{\psi}$也同样约束在一个很小的$\beta$水平之下。也就是说,当$H_0$为真时,希望功效$\rho_{\psi}$越小越好;而当$H_0$为假时,希望功效$\rho_{\psi}$越大越好。这与区间估计问题中,既要保证可靠度又要求精度的矛盾是类似的。NP理论约定,首先让保证犯第一类错误的概率在$\alpha$水平之下,然后尽可能的降低犯第二类错误的概率,也就是要让功效$\rho_{\psi}$尽可能的大。剩下的问题就是功效该如何计算了。因为 $$ \begin{aligned} \rho_{\psi} &= P(\overline{x} > C) = 1 - P(\overline{x} !\leq! C) \ &=1 - P(\frac{\overline{x} - iq}{s / \sqrt{n}} !\leq! \frac{C - iq}{s / \sqrt{n}})\ &= 1-F_{\overline{x}}(\frac{C - iq}{s / \sqrt{n}}) \ \end{aligned} $$ 注意这里与临界值$C$的推导过程不同,构建$t$统计量时我们将$\overline{x}$的均值定为$iq$,也就是假定了$H_1$成立。也就是说在推算$C$时,我们假定$H_0$成立,且让约束$\rho_{\psi}$在$\alpha$水平内;在这里我们假定$H_1$成立,得到$\rho_{\psi}$ 的表达式并尝试让它尽可能的大。前后两次虽然假定不同,但是临界值$C$是一样的,因为一个检验只有一个临界值。现在将$C=100+t_{n-1}(\alpha)\frac{s}{\sqrt{n}}$,代入上式得 $$ \begin{aligned} \rho_{\psi} &= 1-F_{\overline{x}}(\frac{100+t_{n-1}(\alpha)\frac{s}{\sqrt{n}} - iq}{s / \sqrt{n}}) \ &= 1- F_{\overline{x}}(\frac{100-iq}{s / \sqrt{n}}+t_{n-1}(\alpha))\ &= 1- F_{\overline{x}}(- [\frac{iq - 100}{s / \sqrt{n}} - t_{n-1}(\alpha)])\ &= 1- (1 - F_{\overline{x}}(\frac{iq - 100}{s / \sqrt{n}} - t_{n-1}(\alpha)))\ &= F_{\overline{x}}(\sqrt{n} \cdot \frac{iq - 100}{s} - t_{n-1}(\alpha)) \end{aligned} $$ 。现在终于清晰了,当$H_0$为假时,功效$\rho_{\psi}$与4个量有关系:检验水平$\alpha$,$\alpha$越大,$t_{n-1}(\alpha)$越小,功效$\rho_{\psi}$越大;样本容量$n$,$n$越大,功效$\rho_{\psi}$越大;样本标准差$s$,$s$越大,功效$\rho_{\psi}$越小;药物的效果$iq - 100$,也就是处理因素效果越好(差值越大),功效$\rho_{\psi}$越大。通常我们约定一个检验的功效最小要达到$0.8$。
假如我们选择$\alpha = 0.05$,$\rho_{\psi} = 0.8$的话,那么也就是第一类错误的概率将$\leq 0.05$,第二类错误的概率将$\leq 0.2$。了解了功效与那些量有关后,下面来思考一下功效的意义。功效指的是当使用检验$\psi$时$H_0$被拒绝的概率,所以功效越大,$H_0$被拒绝的概率越大。也就是说当一个检验的功效较大时,我们得到拒绝$H_0$的结果越可靠,重现性越好。但在实践中,一定要结合与功效相关的$4$个量来综合考虑。$4$个量中,检验水平$\alpha$对功效的影响一般可以忽略。样本标准差$s$越大功效越小,但这里要注意的是样本标准差$s$是对总体标准差$\sigma$的估计,因此只要我们努力让随机抽样是理想的、没有偏差的,那么标准差$s$对功效的影响也视为恒定的;处理因素的效果,其实在检验开始前已经确定了,它本质上是与检验无关的量,所以也可视为不变的;最后也是最关键的样本容量$n$,当$n$增加时功效跟着增加,这是我们期望看到的。但是当处理因素效果并不明显,一味的增加样本容量,也能提升功效,也将会得到稳定的拒绝$H_0$的判断。所以样本容量实际上是一把双刃剑。
大功即将告成,还差最后一个任务,也就是计算$p$值。详见P值到底是什么?