
P值到底是什么?

P值的意义
教科书及其他参考资料中,不乏关于P值的准确定义,即:当无效或无差异的零假设成立时,检验统计量取当前值及更加极端值的概率。但实践应用中对P值的误解和滥用仍屡见不鲜。
统计学主要任务之一的假设检验,要求我们在面对诸如:“样本平均数是否与理论值存在差异?”这样的问题时,首先建立一对对立的假设,即“零假设”和“备择假设”。
零假设认为,样本平均数与理论值没有差异(所以零假设又称无效假设,意指某项处理因素是无效的);备择假设则反之。如果零假设成立,即意味着,我们所观察到的样本平均数与理论值之间的差异是由随机因素造成,或者说是偶然出现的。例如,假设理论值是1.0,三个样本观测值分别取1.1,1.2,0.9,因此样本均值约为1.066667,与理论值之差为0.066667。这0.066667的差异是由测量时的随机误差造成的。
此时,我们用双尾t检验的计算过程将是这样的:
首先,考虑到样本容量$3<30$属于小样本,以及理论分布的方差未知,因此我们须要用t分布来描述样本均值的分布。根据样本均值$\overline{x}$、理论均值$\mu$和样本标准误$\frac{s}{\sqrt{n}}$来计算t值,公式和计算如下。 $$ t = \frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}=\frac{1.066667 - 1}{\frac{0.1527525}{\sqrt{3}}} = 0.7559289 $$
以上公示定义的t统计量,实际上是对样本均值的标准化。且其中隐含了一个重要假定,即:“样本是抽样自均值为1.0的正态总体的“。该隐含假定与零假设是等价的,所以通过该公式计算而得t值,以及后续的概率计算(P值),就有了“零假设成立”的条件。
然后,根据t值表,当自由度$df = 2$时,$|t_{2,0.05}| = 4.302653$,所以 $t < |t_{2,0.05}|$,得结论在0.05的显著水平下,应该接受零假设。
最后,计算P值,定义已明确表明P值是当无效或无差异的零假设成立时,检验统计量取当前值及更加极端值的概率。这里零假设成立的前提条件已经满足了,检验统计量$t$当前等于0.7559289,那么去当前值及更加极端值的概率是多少呢?从t分布的概率密度函数中不难算出,等于0.5286,也就是P值等于0.5286。下图中蓝色区域的面积也就是我们求的的P值。
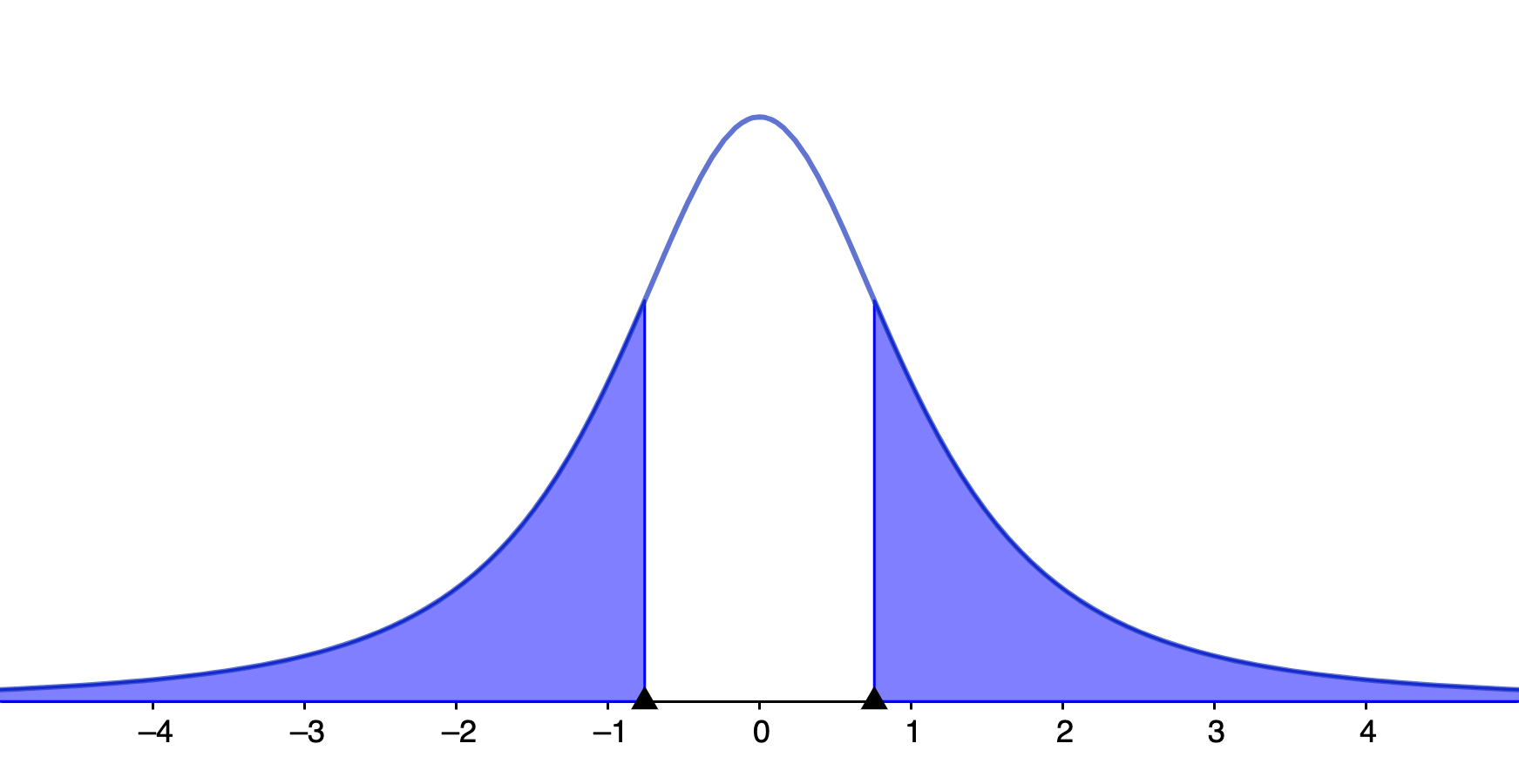
那么这里的P值为0.5286具体应该如何解释呢?
在上例中,P值0.5286是当零假设成立时,得到检验统计量t大于等于0.7559289的概率,或者得到样本均值与理论值之差大于等于0.066667的概率。
概率为0.5286的事件是容易发生的,也就是说由随机测量误差造成0.066667甚至更大的均值之差是很可能发生的。所以现有证据远不足以否定零假设。
换作置信区间的语言,由于样本均值95%的置信区间为 (0.6872084, 1.4461250),包含了理论值1.0,同样应该接受零假设。
如果把第三个样本取值改为1.2,即三样本取值分别为1.1,1.2,1.2。再进行t检验,得$t = 5$;$P = 0.03775$;95%置信区间为 (1.023245, 1.310088)。仍然取0.05的显著性水平,P值 0.03775 < 0.05,因此应该拒绝零假设,转而接受备择假设。
同理,P值0.03775是当零假设成立时,得到检验统计量t大于等于5的概率,或者得到样本均值与理论值之差大于等于0.166667的概率。
概率为0.03775的事件是小概率事件,不容易发生。也就是说由随机测量误差造成0.166667甚至更大的均值之差是发生的概率很小。所以我们有足够的信心认为零假设是不成立的,也就说三样本应该是抽自均值不等于1.0的正态总体的。
从不同的角度讲,P值是对“意外”的测度,也就是样本来自均值为1.0的正态总体的前提下,测量得到样本均值与理论值的差异出现的可能性。离理论值越近的样本均值出现的可能性越大,这是正态分布的性质告诉我们的。那么如果零假设成立时,我们得到一个离理论值较远的样本均值,那就纯粹是“运气”、“意外”了,因为它发生的概率要小。或者我们关于零假设的前提是错误的,样本是抽自另一个正态总体的。
检验的功效
基于P值的假设检验,采用的基本逻辑是,想要证明备择假设成立,需要证明所得数据不支持零假设。对不支持零假设的判断是由分析人员根据P值而做出的,数学工具不能做出假设是真是假的判断。所以假设检验的数学框架中,实际上包含了四种可能性的:
-
零假设为真时,接受零假设;
-
零假设为真时,拒绝零假设(第一类错误、弃真概率$\alpha$);
-
零假设为假时,接受零假设(第二类错误、存伪概率$\beta$);
-
零假设为假时,拒绝零假设(检验的功效$1-\beta$)。
面对任何实际问题应用检验方法时,我们不可能证明零假设是否为真,所以不管接受还是拒绝零假设都有犯错的可能。其中第四种情况的概率,即检验的功效,也就是差异被检测出来的概率。通常我们在完成一个研究时功效至少应该是0.8。为什么在假设检验时必须考虑检验的功效呢?
因为,我们不仅要求在某一次检验中拒绝不成立的零假设,也就是得到小于显著性水平的P值,而且还要能够在多次检验中重现这种结果。比如在上面第二个例子中,我们得到了P值0.03775,计算检验的功效 (R函数:Power.t.test(n=3, delta=0.166667, sd=0.05773503, sig.level=0.05)) 仅为0.7528399。也就是说从均值为1.166667、标准差为0.05773503的总体中随机抽取三个样本进行100次同样的检验,其中有约75%的检验会得到P值小于显著性水平0.05。
影响检验功效的因素有三:
- 显著性水平。显著性水平$\alpha$越大,即弃真概率增大,第二类错误存伪概率$\beta$降低,功效则增大。
- 偏差的大小。样本均值与理论值间的偏差越大,越容易被检出,由处理因素的实际情况决定。
- 样本容量。样本容量越大,第二类错误的概率越低,即$\beta$越低。Neyman-Pearson假设检验理论中对第二类错误的约束,就是通过对样本容量的控制实现的。
- 测量误差。精确度越高的测量得到样本数据的偏差越小,也就是样本标准差越小,那么样本均值与理论值间的偏差越容易被检出。由实验系统的误差控制决定。
其中样本容量是最值得推敲的因素。增加样本容量,可以有效的提高功效,在上面第一个例子中,P值等于0.5286的不显著结果。现在我们来模拟从均值为1.066667、标准差为0.1527525的总体中抽出100个样本,再进行一次t检验,将会发现P值变为了0.0003043,远小于显著性水平。而此时的检验功效为0.8667374。
当样本容量增加时,检验结果截然相反,由之前的接受零假设,变成拒绝零假设,而且功效较大。也就是说当样本容量足够时,即使0.066667这样的微小偏差也可以有效的检出。
计算假设检验的功效,在统计分析实践中往往会被忽视。造成的后果是,当功效较低时,虽然能够观测到偏差,但不能得出统计意义上的显著性,造成假阴性结果。而有些时候,这样的结果代价是巨大的,比如比较两种药物的副作用时,由于样本量不够而得出两种药物同样安全的结论。另一方面,当为了刻意追求显著性结果,而增加样本容量,得到较高功效时,即使非常微小的偏差也能被有效检出。而这种微小的偏差并没有实际的意义。
关于P值的常见错误
P值不能作为统计证据的衡量指标
当两组统计分析得到两个不同的P值时,或许有人会想比较两个P值的大小,以期从中解读更多的信息。这其实是徒劳的,因为P值不能作为衡量统计证据强弱的指标。能够作为一种衡量指标,首先需要满足一个基本条件,即相同的P值能够表达相同的证据强度。这一点P值不能满足的。比如,有两组试验分别得到相同的P = 0.03,但两组试验的样本容量不同,一个为11,另一个为98。虽然在0.05的显著性水平下,零假设都被否定了,两组试验所获得现有证据对零假设的否定程度是不同的。样本容量小的试验,功效往往低于样本容量大的试验,小样本试验组得到较小的P值,很可能是因为其考察的处理效应偏差较大。而对于大样本试验组,在大样本的优势下,并不能得到更低的P值,表明大样本试验组面对的处理效应偏差较小。对于零假设的否定,显然处理效应偏差越大,否定的程度越大;处理效应偏差越小,否定的程度越小。因此,P值仅对一次试验设计下的一组观察数据有意义。
为P值赋予实际意义
P值的大小与样本均值与理论值之差的实际意义无关。统计意义上的显著性,并不代表实际意义上的显著性。当我们对一个确实有很大影响的处理因素(可以得到与理论值偏离很大的样本均值)进行考察时,也就是是实际意义上是有显著性的,我们会得到较小的P值。但当对一个影响很小的处理因素,搜集足够多的数据时,也可得到较小的P值。此时虽然实际差异较小,但这种小差异的确定性被大量样本数据固定了下来了。所以得到统计意义上显著的结果,并不意味着我们真正关心的处理因素有实际价值。
忽视基础概率
当一项研究得到较低的P值时,如0.001,往往会错误的理解为:这个接受备择假设即处理因素有效的结果错误的概率只有0.001。而实际上,在P值小于显著性水平的情况下,发生假阳性判断的可能性是不能被忽视的。P值是在无效假设的前提下计算得到的,它表示当前数据及更极端数据出现的可能性,而不是处理因素有效的可能性。处理因素有效(即样本均值与理论值有实质差异)的概率,称为基础概率。当应对基础概率很低的处理因素时,发生假阳性判断的可能性则更高。例如在对100种癌症药物进行是否有效的检验中,基础概率即药物有效的概率只有10%,检验功效为0.8时,10种真正有效的药物被检出的只有约8种,显著性水平设为0.05时,即有5%的可能将无效判定为有效($90 \times 0.05 \approx 5$),所以真有效的8种和假有效的5种,其中假阳性的概率高达0.38。
被夸大的效应
上述关于功效的讨论告诉我们,当样本均值与理论均值偏差加大时,也就是处理效应较大时,偏差越容易检出,即更容易得到小于显著性水平的P值。假设某种药物对某症状的减轻程度平均为30%,对于同样的样本量,我们的患者可能运气不好,他们对药物不敏感;也可能这组受试对象恰好达到平均水平30%,但样本量不足以证明统计上的显著性,因此被置之不理了;也有可能这组受试对象运气非常好,他们用药后症状的减轻程度远超过30%,比如50%,这样即使低样本量也能得到统计上显著的结论。糟糕的是,如果仅仅基于P值小于显著性水平的试验,我们夸大了药物的效果。这种现象被称为真理膨胀或赢者灾难。有趣的是被扩大的效应往往出现在某个问题的开创性论文中 (因为大多数杂志都喜欢统计上显著的结论),而后续的研究就不会那么夸张了。
非此即彼的二分法
“统计意义上的显著”与“统计意义上的不显著”被我们的大脑自然的分为截然不同的两类,这是人性和认知的习惯。当计算得到P值大于显著性水平时,很多作者会声称:“实验组与对照组不存在差异 (no difference between two groups)”。这种仅仅因为统计上不显著 (statistically non-significant) 的差异而得出不存在差异的结论,是错误的。此外,一个统计上具有显著性的结果与另一个统计上不显著的结果之间,很可能并不矛盾。假设检验中的任何判断都有犯错误的可能。即使研究人员可以进行重复一项完美的实验,每次都有0.8的功效达到P < 0.05,一个获得P < 0.01,而另一个P > 0.30一点也不奇怪。所以无论P值是小是大,都值得谨慎对待。
如何实践假设检验
2016年,美国统计协会在The American Statistician杂志上发表文章“The ASA Statement on P-Values: Context, Process, and Purpose”,警告滥用统计意义和P值。2019年Valentin Amrhein、Sander Greenland、Blake McShane和其他800多个署名人,在Nature杂志发表题为“Retire statistical significance”的文章,再次呼吁研究者和期刊编辑放弃统计学意义之类的术语。除了建议在我们的文章中以合理的精度给出P值 (如P = 0.022),废弃二进制不等式或星号标记,Amrhein等还提出了一个具有建设性的意见:将“置信区间”更名为“兼容性区间”,并以避免过度自信的方式解释它们。具体而言,他们建议研究人员描述区间内所有值的实际影响,特别是观察到的效果 (或点估计) 和限制。
同时作者还特别指出了以下四个事实:首先,区间内的值与数据最兼容,并不意味着区间以外的值不兼容,它们只是兼容性较低而已。其次,区间内所有的值并非与数据同等兼容。点估计是最兼容的,它附近的值比接近极限的值更兼容。第三,就像它产生的0.05阈值一样,用于计算区间的默认范围95%本身是任意约定的。最后,兼容性评估取决于用于计算区间的统计假设 (模型) 的正确性。在实践中,这些假设也受到相当大的不确定性的影响。尽可能清楚地说明这些假设,并测试我们可以测试的假设。
包括放弃统计学意义在内,还有一些其他改进统计学实践的提议,如分享分析方案和结果、报告假阳性率和结合认知规律图文并茂等(详见:“Five ways to fix statistics”)。实际上正确理解假设检验的原理以及P的意义,指导具体应用的关键是对随机性的正确理解,以及假设检验其实是一种应对随机性的数学方法。以大数定律和中心极限定理为基础的概率论,从不确定的随机性中发现确定性。比如服从正态分布的随机变量,每一个具体的取值是不确定的,但整体上随机变量会表现出向均值集中,且集中程度由方差决定的规律。所以在整体层面的规律是确定的,但个体层面就不确定了,一切皆有可能。从均值一大一小的两个的总体中,抽出的样本进行均值比较时有可能得到与总体均值关系相反的结果。
因此,勇于拥抱随机性、具体问题具体分析、综合全面地看待检验结果,应该是假设检验实践主要指导方针。