
单(随机)变量的概率分布(2)
连续变量的概率分布
正态分布
历史上最早得到正态分布的功劳应该归于法国数学家亚伯拉罕·棣莫弗(Abraham de Moivre),后来另一位法国数学家皮埃尔-西蒙·拉普拉斯(Pierre-Simon Laplace)又对棣莫弗的结果进行了完善。与拉普拉斯同时期的德国大数学家约翰·卡尔·弗里德里希·高斯(Johann Carl Friedrich Gauss)在研究测量误差时,从另一个角度也推导出了正态分布,并率先将其应用于天文学研究,高斯的这项工作对后世的影响极大,使得正态分布同时有了“高斯分布”的名称。那么,棣莫弗又是如何在280多年前(1733年)得到正态分布的呢?故事还得从二项分布说起。
设有$2N$个服从$p=1/2$两点分布的随机变量$X_1,X_2,...X_{2N}$,同时令$X_i$的两个对立的结果分别为$1$和$-1$,沿用掷硬币的例子,这里相当于掷$2N$个同等质量的硬币,然后正面向上的记$1$分,反面向上的记$-1$分。那么总分数$S_{2N} = X_1 + X_2 + ... + X_{2N}$。假如这样的掷硬币过程重复多次,$S_{2N}$的平均会有多少分呢?根据数学期望的定义, $$ E(S_{2N}) = \sum_{i=1}^{2N} E(X_i) = \sum_{i=1}^{2N} [1\cdot\frac{1}{2} + (-1) \cdot \frac{1}{2}] = 0 $$ 。因为$X_i$表示的是第$i$个掷出的硬币是正面或反面,所以$S_{2N}$实际上也就是正面比反面多的个数。类似地,还可以得到$S_{2N}$的方差, $$ Var(S_{2N}) = E(S_{2N}^2) - [E(S_{2N})]^2 = E(S_{2N}^2) = \sum_{i=1}^{2N} E(X_i^2) = \sum_{i=1}^{2N} [1^2 \cdot \frac{1}{2} + (-1)^2 \cdot \frac{1}{2}] = 2N $$ 。根据上文中关于二项分布的讨论,$S_{2N}$是服从二项分布的,而且不难看出$S_{2N}$只能取偶数值,因为在掷出的$2N$个硬币中,正面比反面多的个数只能是偶数。所以,根据二项分布的概率公式有$S_{2N} = 2k$的概率为 $$ P(S_{2N} = 2k) = C_{2N}^{N+k} \cdot (\frac{1}{2})^{N+k} \cdot (\frac{1}{2})^{N-k} = \frac{(2N)!}{(N-k)!(N+k)!} \cdot (\frac{1}{2^{2N}}) $$ 下面一个重要的公式——斯特林公式就该登场了:$n! ! \approx! n^n e^{-n} \sqrt{2 !\pi! n}$,代入上式有
当$N !\rightarrow !+\infty$式,上式中$(1-k/N)^{N-k+\frac{1}{2}} (1+k/N)^{N+k+\frac{1}{2}} !\approx! e^{\frac{k^2}{N}}$,所以可得 $$ \frac{2N!}{(N-k)!(N+k)!} \cdot (\frac{1}{2^{2N}}) !\approx! \frac{1}{\sqrt{\pi !N}} e^{-\frac{k^2}{N}} $$ ,调整一下形式有 $$ P(S_{2N} = 2k) = C_{N-k}^{2N} \cdot (\frac{1}{2})^{N+k} \cdot (\frac{1}{2})^{N-k}! \approx !\frac{2}{\sqrt{2 \pi !\cdot (2N)}} e^{-\frac{(2k)^2}{2 \cdot !2N}} $$ 这与正态分布的概率密度公式 $$ f(x) = \frac{1}{\sqrt{2\pi} \sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}} $$ 已经非常接近了,其中均值$\mu = 0$,方差$\sigma^2 = 2N$,分别等于$S_{2N}$的期望$E(S_{2N})$和方差$Var(S_{2N})$ 。惟一的差别是常数项的分子为$2$,而正态分布的概率密度公式的相应因子为$1$。这一点差异恰恰说明了上面我们已经提到的事实,即$S_{2N}$取奇数值的概率为0,所以$S_{2N}$取偶数值的概率是所期望的$2$倍。
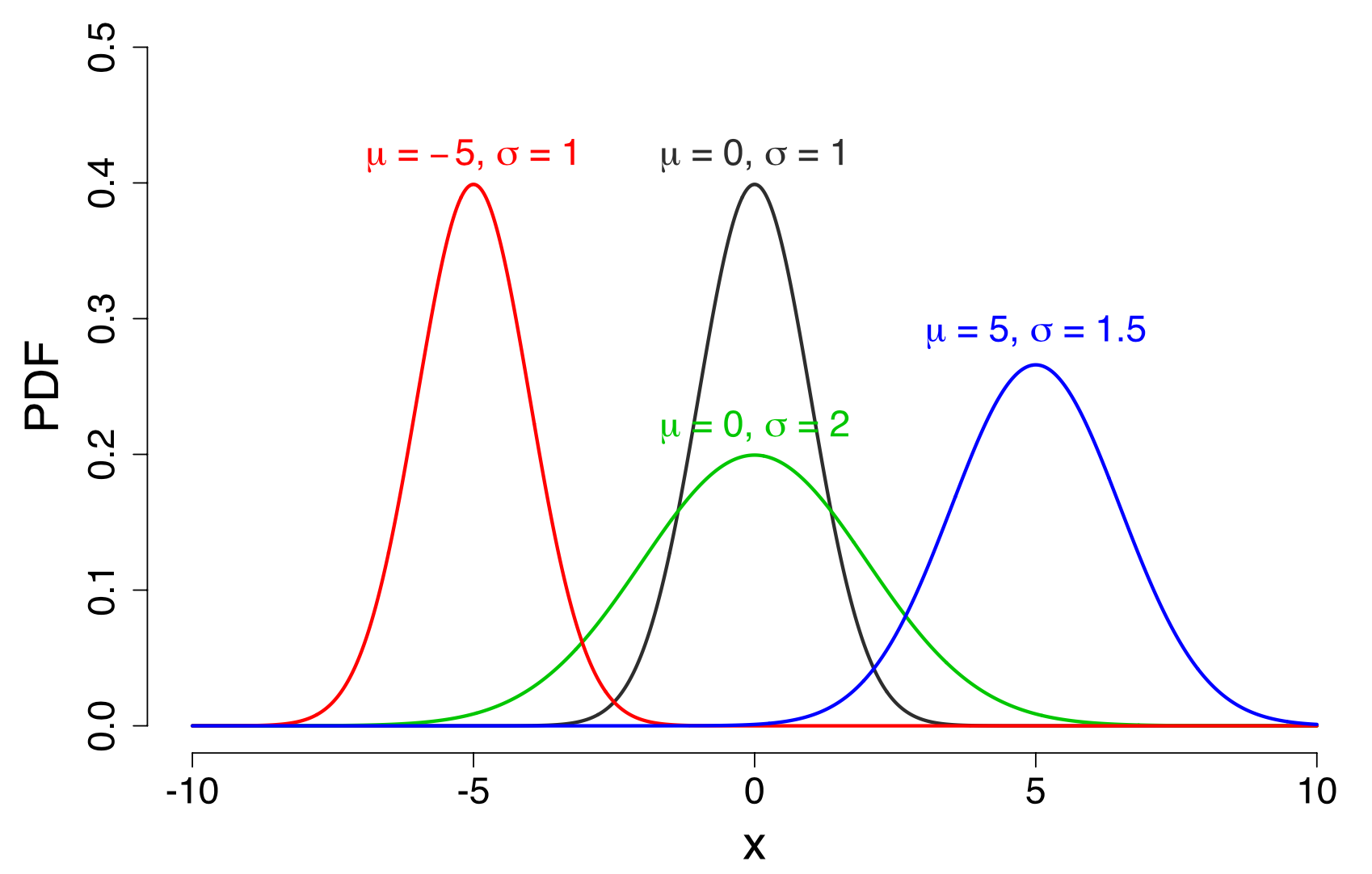
当随机变量$X$服从正态分布,即$X ! \sim ! N(\mu, \sigma^2)$时,$X$的一个函数$Y=\frac{X - \mu}{\sigma}$的概率密度函数,根据随机变量函数的概率密度的一般求法,有 $$ f(y) = f(\sigma ! y + \mu)|\sigma| = |\sigma ! | \frac{1}{\sqrt{2\pi} \sigma} e^{-\frac{(\sigma ! y + \mu -\mu)^2}{2\sigma^2}} = \frac{1}{\sqrt{2\pi}} e^{-\frac{y ^2}{2}} $$ 所以,$Y$服从$\mu = 0, \sigma =1$的正态分布,即标准正态分布。
卡方分布
卡方分布是三大抽样分布之一,总是在假设检验中出现。如果随机变量$X$服从自由度为$n \geq 0$的卡方分布,那么$X$具有概率密度函数 $$ f(x) = \frac{1}{2^{\frac{n}{2}} \Gamma(\frac{n}{2})} x^{\frac{n}{2} - 1} e^{-\frac{x}{2}}, \, x \geq 0 $$ 记作$X \sim \chi^2(n)$。卡方分布中自由度$n$对分布的形状影响极大。在统计学中,很多假设检验的检验统计量在原假设下服从卡方分布,这类假设检验尤其适用于分类数据。卡方检验是一种非参数检验,也就是说它对数据来源的总体分布不做任何假设(但相比于参数检验,卡方检验的统计效果差)。
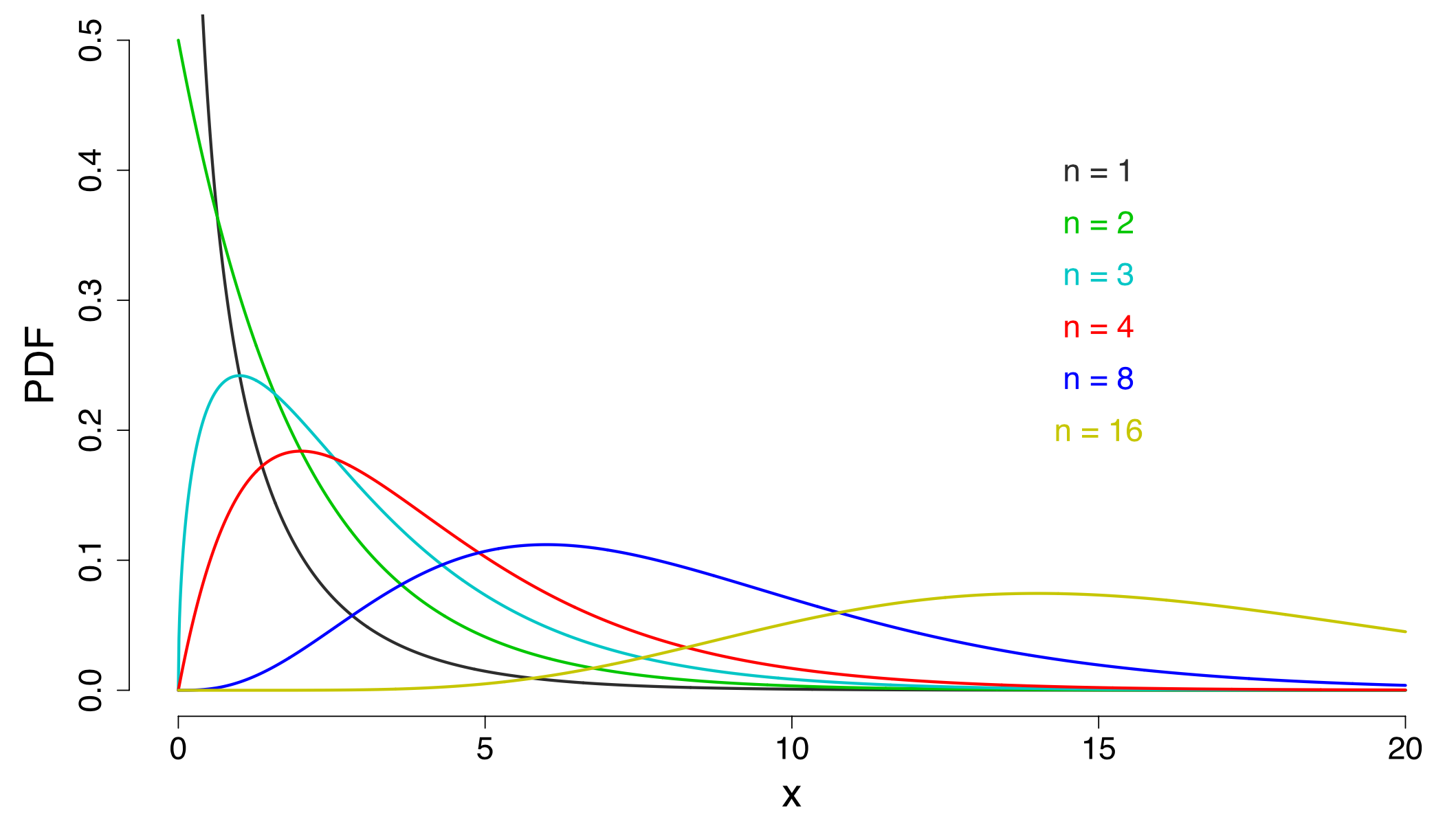
卡方分布是由相互独立且均服从正态分布的随机变量的平方之和构成的。最简单的情形是这样的,假设随机变量$X$服从标准正态分布,即$X !\sim !N(0,1)$,那么$X^2$服从自由度为$1$的卡方分布,即$X^2 !\sim! \chi^2(1)$。为证明这一重要结果,先令$Y = X^2$,那么随机变量$Y$的概率分布函数可写为 $$ \begin{aligned} F_Y(y) &= P(Y ! \leq ! y) \ &= P(X^2 ! \leq ! y) \ &= P(-\sqrt{y} ! \leq ! X ! \leq ! \sqrt{y}) \end{aligned} $$ 代入$X$的概率分布函数,并求导 $$ \begin{aligned} F_Y(y) &= F_X(\sqrt{y}) - F_X(-\sqrt{y})\ f_Y(y) &= F_X^{\prime}(\sqrt{y}) \cdot (\sqrt{y})^{\prime} - F_X^{\prime}(-\sqrt{y}) \cdot (-\sqrt{y})^{\prime} \ &= f_X(\sqrt{y}) \cdot \frac{1}{2\sqrt{y}} - f_X(-\sqrt{y}) \cdot \frac{-1}{2\sqrt{y}}\ &= \frac{f_X(\sqrt{y})}{\sqrt{y}} \ &= \frac{1}{\sqrt{2\pi}} e^{-\frac{y}{2}} y^{-\frac{1}{2}} \quad (\because\Gamma(\frac{1}{2}) = \sqrt{\pi})\ &= \frac{1}{2^{\frac{1}{2}}\Gamma(\frac{1}{2})} y^{\frac{1}{2} - 1} e^{-\frac{y}{2}} \end{aligned} $$ 所以随机变量$Y$服从自由度为$1$的卡方分布,并且数学期望为$1$,方差为$2$。从一个服从标准正态分布随机变量的平方,推广到$k$个标准正态分布随机变量的平方之和,对应的卡方分布会在自由度上由$1$变为$k$。设一个正整数$k$,从$X_1$到$X_k$是$k$个独立且同为标准正态分布的随机变量,那么就有$Y_k = X_1^2 + X_2^2+...+X_k^2$,服从自由度为$k$的卡方分布,即$Y_k \sim \chi^2(k)$。卡方分布具有可加性,即$Y_k = Y_i + Y_{k-i},\,(1<i<k)$。所以假设有$Y_{n_1},Y_{n_2},...,Y_{n_m}$,$m$个相互独立且均服从卡方分布的随机变量,那么它们的和$Y=Y_{n_1}+Y_{n_2}+...+Y_{n_m}$服从自由度为$n_1+n_2+...+n_m$的卡方分布。
卡方分布要求构成它的随机变量服从标准正态分布,如果这些随机变量服从一般的正态分布(均值不同、方差相同),即$X_i ! \sim ! N(\mu_i, \sigma^2)$,那么此时$Y_n = \sum_{i=1}^{n} X_i^2$服从自由度为$n$的非中心卡方分布,有概率密度函数 $$ f(x) = \sum_{m=0}^{\infty} \frac{(\frac{\delta}{2})^m}{2^{m+\frac{n}{2}}m! \Gamma(m+\frac{n}{2})} x^{m+\frac{n}{2} - 1} e^{-\frac{x+\delta}{2\sigma^2}} \sigma^{-4m -n}, \, x > 0 $$ 其中$\delta= \sum_{i=1}^n \mu_i^2$称为非中心参数,有数学期望$E(X)=\delta ! + n \sigma^2$和方差$Var(X)=2n\sigma^4 + 4\sigma^2 \delta$。
从同一正态总体$N(\mu,\sigma^2)$中抽取的相互独立的$n$个随机变量$x_i, (i=1,2,...,n)$,它们的联合分布仍为正态分布,且有概率密度函数 $$ f(x_1,x_2,...,x_n) = [\frac{1}{\sqrt{2\pi} \sigma}]^n e^{-\frac{1}{2} \sum_{i=1}^{n}(\frac{x_i-\mu}{\sigma})^2} = [\frac{1}{\sqrt{2\pi} \sigma}]^n e^{-\frac{1}{2} \cdot \chi^2(n)} $$ ,这里指数部分出现的$\sum_{i=1}^{n}(\frac{x_i-\mu}{\sigma})^2$也就是自由度为$n$的$\chi^2$。
$t$分布
$t$分布是第二个重要的抽样分布。在假设检验中,来自某正态总体$N(\mu,\sigma^2)$的一组样本$x_1,x_2,...,x_n$其平均数的$\overline{x}$的函数$z=\frac{\overline{x}-\mu}{\sigma/\sqrt{n}}$,统计量$z$服从标准正态分布。因为每次抽出一组样本,会得到可能有变化的$\overline{x}$,所以$\overline{x}$也是一个随机变量,而且有均值$\mu$和标准差$\sigma/\sqrt{n}$(又称标准误)。根据上述标准正态分布的推导过程,不难理解$z ! \sim ! N(0,1)$。有了这个结论就可以完成假设检验的统计推断。但是如果正态总体的标准差$\sigma$未知,统计量$z$就不存在了。实践中我们会用样本标准差来代替(估计)总体标准差,构造出来的新的统计量,用$t$表示,即$t=\frac{\overline{x}-\mu}{s/\sqrt{n}}$。此时的$t$不再服从标准正态分布。
如何得到$t$统计量的概率密度函数?我们得从$ Y=\frac{X - \mu}{\sigma} ! \sim ! N(0,1)$说起。
假设有随机变量$X! \sim !N(\mu,\sigma^2)$,产生一组样本$x_1,x_2,...,x_n$,因为$Y !\sim! N(0,1)$,所以$\sum_{i=1}^n (\frac{x_i - \mu}{\sigma})^2$服从自由度为$n$的$\chi^2$分布。将$\sum_{i=1}^n (\frac{x_i - \mu}{\sigma})^2$进行分解,得到 $$ \begin{aligned} \sum_{i=1}^n (\frac{x_i - \mu}{\sigma})^2 &= \frac{1}{\sigma^2} \sum_{i=1}^n(x_i - \mu)^2 = \frac{1}{\sigma^2} \sum_{i=1}^n [(x_i - \overline{x}) + (\overline{x} - \mu)]^2 = \frac{1}{\sigma^2} \sum_{i=1}^n [(x_i - \overline{x})^2 + (\overline{x} - \mu)^2 - 2(x_i - \overline{x})(\overline{x} - \mu)]\ &= \frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \overline{x})^2 + \frac{1}{\sigma^2} \sum_{i=1}^n (\overline{x} - \mu)^2 + \sum_{i=1}^n2(x_i - \overline{x})(\overline{x} - \mu) \end{aligned} $$ ,其中由于$\overline{x} - \mu$是一个常数,所以$\sum_{i=1}^n (\overline{x} - \mu)^2 = n(\overline{x} - \mu)^2$,且$\sum_{i=1}^n (x_i - \overline{x})=0$,因此$\sum_{i=1}^n2(x_i - \overline{x})(\overline{x} - \mu) =0$,所以 $$ \sum_{i=1}^n (\frac{x_i - \mu}{\sigma})^2 = \frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \overline{x})^2 + \frac{n}{\sigma^2}(\overline{x} - \mu)^2 = \frac{(n-1)\frac{\sum_{i=1}^n (x_i - \overline{x})^2}{n-1}}{\sigma^2} + (\frac{\overline{x} - \mu}{\sigma / \sqrt{n}})^2 = \frac{(n-1)s^2}{\sigma^2} + (\frac{\overline{x} - \mu}{\sigma / \sqrt{n}})^2 $$ 现在请仔细观察上式,等号最左边$\sum_{i=1}^n (\frac{x_i - \mu}{\sigma})^2 \sim \chi^2(n)$,最右边第二项,由于$\frac{\overline{x}-\mu}{\sigma/\sqrt{n}} !\sim! N(0,1)$,所以$(\frac{\overline{x} - \mu}{\sigma / \sqrt{n}})^2 !\sim! \chi^2(1)$。根据卡方分布的可加性,可知等号右边第一项$\frac{(n-1)s^2}{\sigma^2} !\sim! \chi^2(n-1)$(该结论也用于方差的区间估计)。
现在我们再回到$t$统计量的定义,并作变形,得到 $$ t=\frac{\overline{x}-\mu}{s/\sqrt{n}} = \frac{\overline{x}-\mu}{\sqrt{\frac{(n-1)\sigma^2}{(n-1)\sigma^2}\cdot\frac{s^2}{n}}} = \frac{\overline{x}-\mu}{\sqrt{\frac{\sigma^2}{n}\cdot\frac{(n-1)s^2}{(n-1)\sigma^2}}} = \frac{\overline{x} - \mu}{\sigma / \sqrt{n}} \cdot \frac{1}{\sqrt{\frac{(n-1)s^2}{\sigma^2}\cdot\frac{1}{n-1}}} $$ 令$z = \frac{\overline{x} - \mu}{\sigma / \sqrt{n}}$,$y = \frac{(n-1)s^2}{\sigma^2}$,所以$t = \frac{z}{\sqrt{y/ (n-1)}}$,其中$z$和$k$分别所代表的是随机变量$Z! \sim ! N(0,1)$和$Y ! \sim ! \chi^2(n-1)$。因此,$t$统计量的概率密度可以利用标准正态分布和卡方分布的概率密度推导出来,首先来看分母部分,令$M = \sqrt{\frac{Y}{n-1}}$。 $$ P(M !\leq! m) = P(\sqrt{\frac{Y}{n-1}} !\leq! m) = P(Y! \leq! m^2(n-1)) = \int_0^{m^2(n-1)} k_{n-1}(m^2(n-1))dy $$ 其中$k_{n-1}$为自由度为$n-1$的卡方分布的概率密度公式。利用积分上限函数的求导公式对$m$求导,得$M$的密度函数$f_M(m) = 2(n-1)m !\cdot! k_{n-1}((n-1)m^2)$。连同$Z$的密度$f_Z(z) = \frac{1}{\sqrt{2\pi}}e^{-z^2/2}$函数,导入随机变量商密度函数的一般公式,得

将$t$替换为常用的随机变量符号$x$,得 $$ f(x) = \frac{\Gamma(\frac{n}{2})}{\sqrt{(n-1)\pi}\Gamma(\frac{n-1}{2})} \bigg(1+\frac{x^2}{n-1}\bigg)^{-\frac{n}{2}} $$ ,该式即是自由度为$n-1$的$t$分布的概率密度函数。
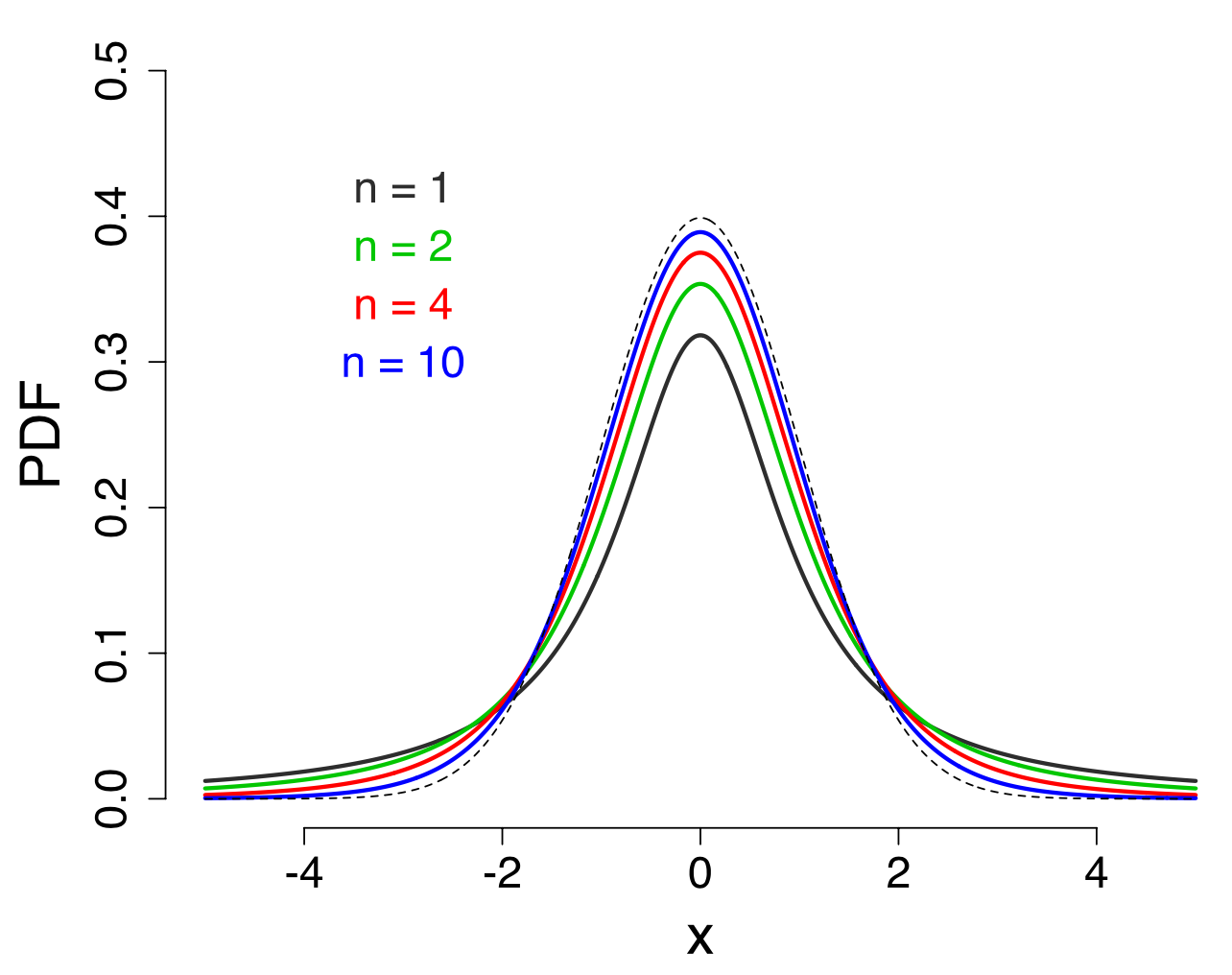
所以在假设检验中,当总体分布的方差$\sigma^2$未知,用样本方差$s^2$来估计,所得的统计量$t = \frac{\overline{x}-\mu}{\sqrt{s^2/n}}$服从自由度$n-1$的$t$分布。
由表达式$t = \frac{z}{\sqrt{y/ (n-1)}}$可知,$t$分布可以理解为由两个随机变量$Z !\sim! N(0,1)$和$Y !\sim! \chi^2(n-1)$构成的函数$\frac{Z}{\sqrt{Y/(n-1)}}$的概率分布。这里假如$Z !\sim !N(\delta, 1)$,那么相应的$t$分布则变为自由度为$n-1$的非中心$t$分布,有概率密度函数 $$ f(x) = \frac{(n-1)^{\frac{n-1}{2}} e^{-\frac{\delta^2}{2}}}{\sqrt{\pi} \Gamma(\frac{n-1}{2}) (n-1+x^2)^{\frac{n}{2}}} \sum_{i=0}^{\infty} \frac{\Gamma(\frac{n+i}{2})}{i!} (\frac{x \delta \sqrt{2}}{\sqrt{n-1+x^2}})^i, \, -\infty < x < +\infty $$ 其中$\delta$称为非中心参数,有数学期望$E(X)=\delta \sqrt{\frac{n-1}{2}} \frac{\Gamma(\frac{n-2}{2})}{\Gamma(\frac{n-1}{2})}, (n>1)$和方差$Var(X)= \frac{(n-1)(1+\delta^2)}{n-3}-\frac{\delta^2(n-1)}{2}(\frac{\Gamma(\frac{n-2}{2})}{\Gamma(\frac{n-1}{2})})^2, \, (n>2)$。
$F$分布
假设检验中的$z$检验和$t$检验是关于样本平均数的检验,而对样本方差的检验需要用到卡方分布或$F$分布。当比较来自两个总体的样本方差之间是否存在显著差异时,会将两样本方差作比值,然后与$1$比较。假设有两个正态总体$N(\mu_1,\sigma_1^2)$和$N(\mu_2,\sigma_2^2)$分别产生两组样本(容量分别为$n$和$m$),样本方差分别为$s_1^2$和$s_2^2$,那么 $$ f=\frac{\frac{s_1^2}{\sigma_1^2}}{\frac{s_2^2}{\sigma_2^2}} = \frac{\frac{(n-1) s_1^2}{\sigma_1^2} \cdot \frac{1}{n-1}}{\frac{(m-1) s_2^2}{\sigma_2^2} \cdot \frac{1}{m-1}} $$ 且已知$\frac{(n-1)s_1^2}{\sigma_1^2} !\sim! \chi^2(n-1)$和$\frac{(m-1)s_2^2}{\sigma_2^2} ! \sim ! \chi^2(m-1)$,所以$f$实际上表示的是两个随机变量$X_1 ! \sim ! \chi^2(n-1)$和$X_2 ! \sim ! \chi^2(m-1)$分别除以各自的自由度后再相除所得的随机变量。首先令$Y = \frac{X_1}{n-1}$, $$ P(Y !\leq ! y) = P(\frac{X_1}{n-1} ! \leq ! y) = P(X_1 !\leq ! y(n-1)) = \int_0^{x_1(n-1)} k_{n-1}(x_1(n-1))dx_1 $$ 其中$k_{n-1}$为自由度为$n-1$的卡方分布的概率密度公式。利用积分上限函数的求导公式对$y$求导,得$Y$的密度函数为$(n-1) !\cdot! k_{n-1}(x_1(n-1))$。同理可得$\frac{X_2}{m-1}$的密度函数为$(m-1) !\cdot! k_{m-1}(x_2(n-1))$。导入随机变量商密度函数的一般公式,得

同样地,用常用的随机变量符号替换,得 $$ f(x) = (n-1)^{\frac{n-1}{2}}(m-1)^{\frac{m-1}{2}}x^{\frac{m-3}{2}} \frac{\Gamma(\frac{m+n-2}{2})}{\Gamma(\frac{n-1}{2})\Gamma(\frac{m-1}{2})} [(m-1)x+n-1]^{-\frac{m+n}{2} + 1} $$ ,即自由度为$n-1$和$m-1$的$F$分布的概率密度函数。
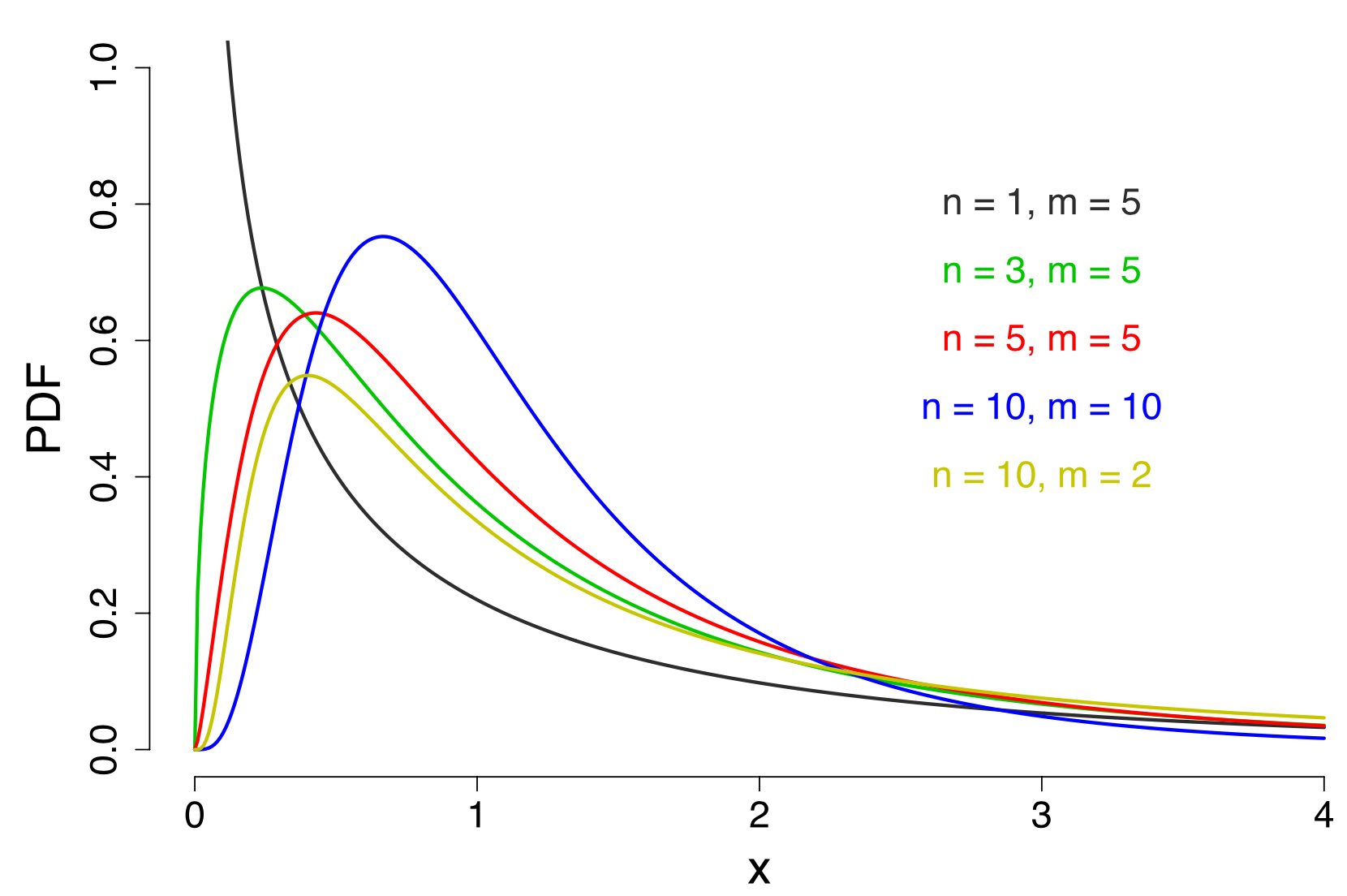
与卡方分布和$t$分布类似,$F$分布也有非中心的$F$分布。在构成$F$分布的两个服从卡方分布的随机变量,只要让出现在分子位置上的随机变量服从非中心卡方分布,$F$分布就实现了非中心化。
柯西分布
柯西分布的概率密度函数为 $$ f(x) = \frac{1}{\pi} \cdot \frac{\sigma}{\sigma^2 + (x - \mu)^2}, \quad -\infty < x < + \infty $$
,其中$\sigma$为尺度参数,$\mu$为位置参数。当$\mu=0,\quad \sigma =1$时的特例称为标准柯西分布。
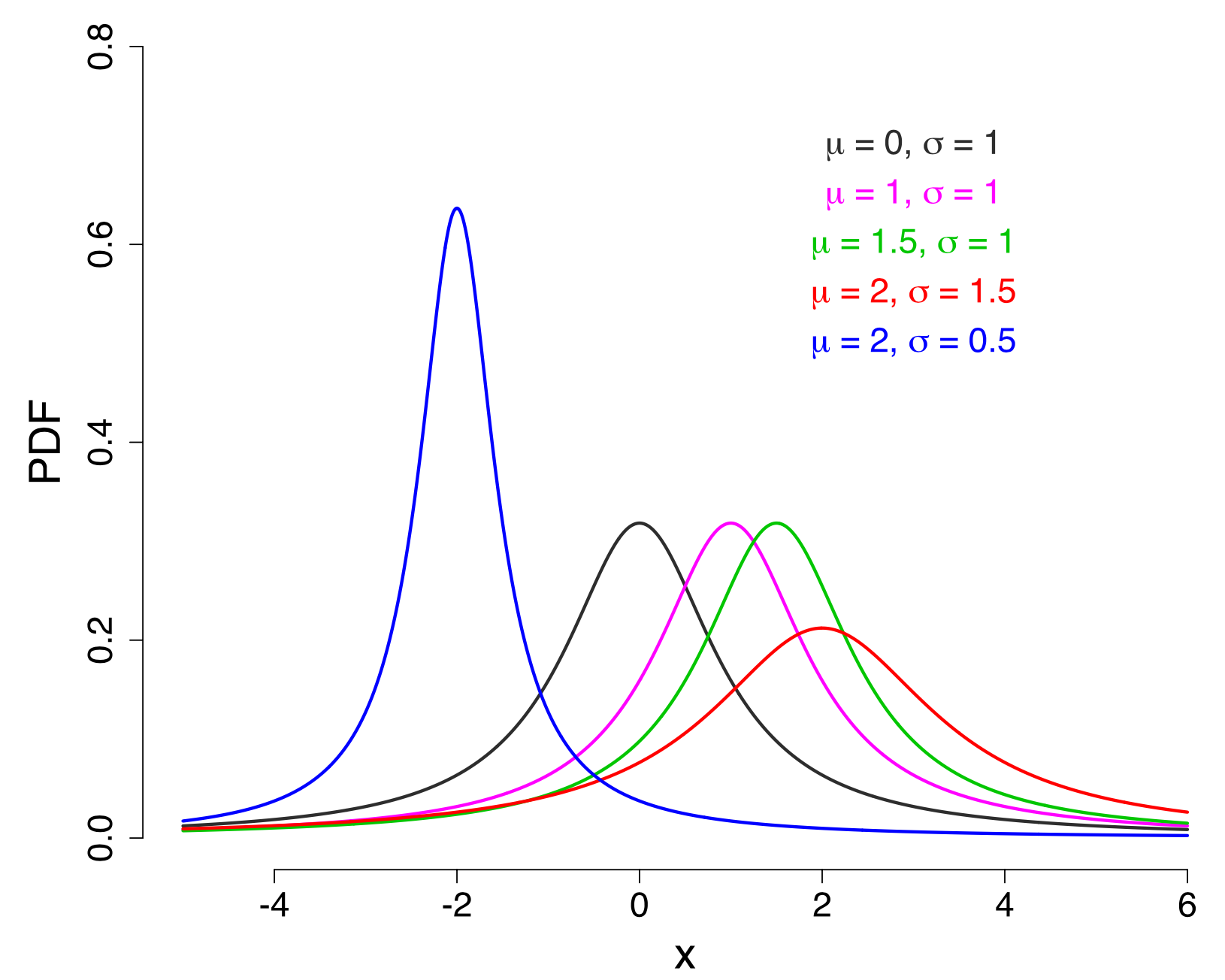
柯西分布是一种非常特殊的概率分布,它的均值和方差不存在,但有中位数和众数,也就是位置参数$\mu$,下四分位数为$\mu-\lambda$,上四分位数为$\mu+\lambda$。
柯西分布具有可加性,即如果有$X_1 ! \sim ! Cauchy(\mu_1, \lambda_1)$和$X_2 !\sim! Cauchy(\mu_2, \lambda_2)$,那么$X_1+X_2 ! \sim ! Cauchy(\mu_1+\mu_2, \lambda_1+\lambda_2)$。
两个标准正态分布之比服从标准柯西分布,标准柯西分布的倒数仍是标准柯西分布。
标准柯西分布还等同于自由度为$1$的$t$分布,而一般的柯西分布等同于自由度为$1$的非标准化的$t$分布。
柯西分布概率密度函数的雏形最早出现于数学家费马的著作(17世纪中叶),后来陆续被牛顿、莱布尼茨、惠更斯、盖多·格兰迪和玛利亚·加塔娜·阿涅西研究过。到了19世纪,这种曲线了一个特殊的名称——“阿涅西箕舌线”。1824年之间柯西密度曲线并没有作为一种可能的误差分布出现,然而当它用于误差研究时,却是作为其他一般定理的反例出现的。而且被发现了两次,更有趣的是两位发现者寻找它的动机不同,并以两种不同的方式解释了它的重要性。1824年,泊松发文首次注意到了具有标准柯西密度函数的概率分布,并发现它具有一些相当特殊的性质,并且可以产生一些统计学中普遍接受的结果的反例。泊松的论文旨在澄清并略微扩展拉普拉斯在最小二乘法方面的一些工作。1810-1811年,拉普拉斯通过证明我们现在所称的中心极限定理,为勒让德的最小二乘原理提供了一个大样本的理由,并指出,由于最小二乘法是处理正态分布误差的最佳方法,它对任何误差分布都是最佳的,至少对大样本是如此。当时,拉普拉斯忽略了任何正则性条件(用于限定定理使用范围的限定条件),只假设误差分布是对称的。在综述拉普拉斯的工作室,泊松呼吁应当特别注意密度函数$f(x) = {\pi(1+x^2)}^{-1}$。他指出,如果对误差分布为$f(x)$的多个观测值取平均值,则随着观测值数量的增加,平均误差不会收敛到零或任何其他数字,而是具有相同的分布,无论观测值数量有多大。虽然泊松清楚地意识到在这一特殊情况下可能出现的困难,但他并不十分重视它。
柯西与柯西分布第一次邂逅源自一场发生在1853年的数学争端,挑起争端的是不太出名的数学家伊瑞·朱尔斯·比内梅(拉普拉斯的忠实信徒),他发文称Cauchy在1835年提出的插值方法与概率论存在冲突,因为它通常不会给出与最小二乘法相同的结果。随后,柯西连发七文反击了比内梅的“挑衅”,当然期间比内梅也做了四次回应。争论最终甚至演变成两人开始互相伤害。柯西坚持认为,虽然这两种方法是不同的,每种方法都有其优点和缺点。但是他认为概率论并没有赋予最小二乘法独特的优势。为了证明他的观点,柯西用特征函数作为工具发现,尽管最小二乘法为正态分布误差提供了“最可能”的值,但在其他情况下却没有。柯西给出了密度函数$f(\epsilon) = \frac{k}{\pi} \cdot \frac{1}{1+k^2\epsilon^2}$作为“其他情况”的例子。柯西论证的力量在于,只有正态分布的最小二乘法才是最好的;与攻击拉普拉斯的证明相比,他更关心的是对特征函数的严格处理和捍卫他的插值方案。在比内梅的回应中,提到了泊松之前工作,之所以忽视柯西密度是因为在实践中不会出现。最后通过拉着拉格朗日、高斯、拉普拉斯和贝塞尔一起为最小二乘法背书。这场争论虽然短暂,但很活跃。柯西为他差值法辩护,通过运用他强大的分析能力证明最小二乘法在线性估计中不具有自然的垄断性。另一方面,比内梅则站在拉普拉斯权威所捍卫的立场上进行辩论,他渴望不让正则性条件干扰他所认为的实际真理。
很难说是谁最后赢的了这场数学争端。他们在不同的前提下争论,两者都是正确的。讽刺的是,在争论的最后一篇文章中,柯西严格证明了中心极限定理,并承诺在未来的文章中探讨其统计意义。但柯西再也没有回到这个话题上来,也许是因为他看到自己正在危险的滑向对手的阵营。
对数正态分布
正态分布之于随机变量概率分布,就像夜空中最闪亮的星,最常被用来描述许多学科的数据中出现的随机变化。然而许多测量结果显示出或多或少的偏态分布。当平均值低、方差大、取值不能为负时,偏态分布尤其常见,例如,物种丰富度、传染病潜伏期的长短以及地壳中矿产资源的分布。这种偏态分布通常符合对数正态分布。设$X$是取正值的连续随机变量,如果$\ln ! X$服从正态分布,则$X$服从对数正态分布,有概率密度函数 $$ f(x) = \frac{1}{x\sqrt{2 \pi} \sigma}e^{-\frac{(\ln ! x - \mu)^2}{2\sigma^2}}, \, x>0 $$ ,数学期望$E(x)= e^{\mu+\frac{\sigma^2}{2}}$和方差$Var(X)=(e^{\sigma^2} -1)e^{2\mu+\sigma^2}$。
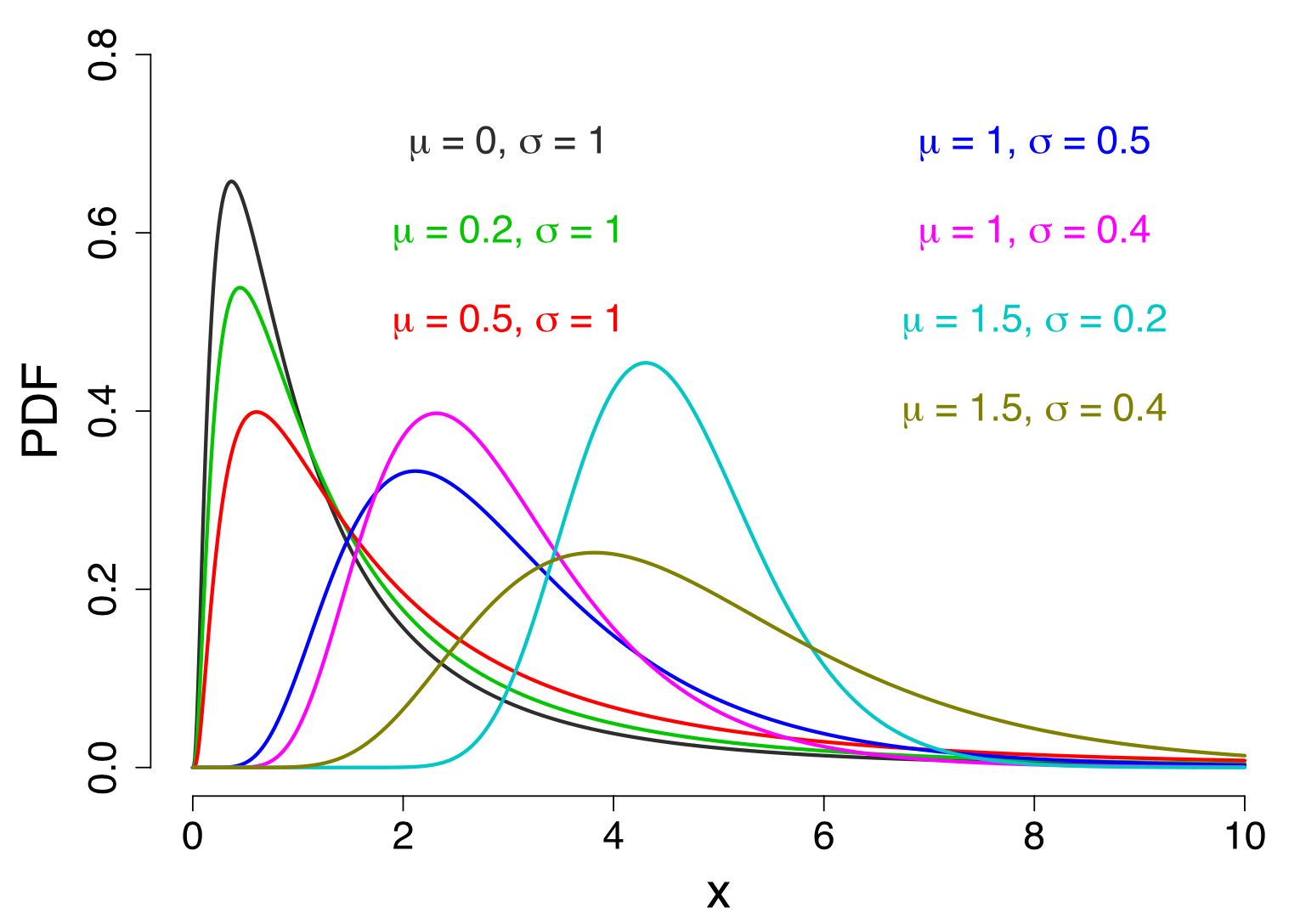
所以正态分布经指数变换后即为对数正态分布;对数正态分布经对数变换后即为正态分布。此外当$\gamma$,$t$是正实数,$X$是参数为$(\mu!,\, !\sigma)$的对数正态分布,则$Y = \gamma ! X^t$仍是对数正态分布,参数为$(t\mu+\ln{\gamma}), t\sigma$。简单来说,对数正态分布之积还是对数正态分布。我们知道正态分布之和仍是正态分布,实际上两者之间是有逻辑关系的。对数正态分布相乘等同于其幂指数相加,而服从对数正态分布的随机变量,如果写成自然底数的次幂形式,那么幂指数服从正态分布。因此对数正态分布之积等同于正态分布之和。
正态分布与对数正态分布之间的关系,与随机变量变异的可加性和可乘性有关。随机变量不同取值的变异性是用方差或标准差来衡量的。我们再观察一下方差的公式$\sigma^2 = \frac{\sum_{i=1}^N(x_i - \mu)^2}{N}$,其意义实际上是每个$x_i$到均值$\mu$的距离平方的平均值。也就是说每个$x_i = \mu ! \pm !\epsilon$,$\epsilon$表示距离(也是一个随机变量),所以这里随机变量的变异性是通过加/减法实现的,即随机变量变异具有可加性。如果随机变量的变异性是通过乘/除法实现的,比如$x_i = \mu !\times / \div !\epsilon$,那么该随机变量的变异则具有可乘性。变异的可加性与可乘性分别导致正态分布和对数正态分布,而正态分布与对数正态分布又分别对应算术平均数和几何平均数。