
单(随机)变量的概率分布(1)
随机变量,即变量的取值由相应的概率决定,可以用来描述随机事件发生结果。例如,掷一颗质地均匀的六面骰子,令变量$X$表示可能出现的结果,显然$X \in {1,2,3,4,5,6}$,且取值的概率$P(X)=\frac{1}{6}$。随机变量根据其取值的数域不同,可分为离散型随机变量(简称离散变量)和连续型随机变量(简称连续变量)。掷骰子例子中的$X$就是典型的离散变量;而实践中常常包含测量误差的变量,如身高、空气温度、电子器件寿命等,则是连续变量。
随机变量取不同值的可能性,由相应的概率定量地描述。对于离散变量,我们用概率质量函数(probility mass function, PMF)表达取不同离散值的概率,例如$P(X=k),k=0,1,2,...$,表示离散随机变量$X$取值为$k$的概率;而连续变量,我们用概率密度函数(probility density function, PDF)来表达取不同值的概率(注意!这里的概率是密度函数在某区间上的积分),例如$f(x), -\infty < x < + \infty$。此外,还会用累积分布函数(cumulative distribution function, CDF),来表达变量取小于等于某值的概率,即$P(X! \leq ! k)$和$F_X(x)$。就连续变量而言,$f(x)$和$F_X(x)$之间有明确的数学关系,概率密度函数是累积分布函数的导函数,即$f(x) = F_X^{\prime}(x)$;而累积分布函数是对概率密度函数求积分而得的,即$F_X(x) = \int_{- !\infty }^x f(t)dt$(为区别于积分上限和累积分布函数的自变量,将概率密度函数的自变量替换为$t$)。离散变量的概率质量函数与累积分布函数之间关系则相对简单,有$P(X !\leq ! k) = \sum_{i=0}^{\lfloor ! k ! \rfloor} P(X=i)$。
数理统计学中大多数常见的随机变量的概率分布之间都是有某种关联的,要么一个分布是另一个分布的特例,正态分布与标准正态分布就是如此,要么一个分布是另一个分布被限制在某种条件下的变形,如二项分布与泊松分布之间的关系。所以,在学习这些概率分布时,了解它们之间的逻辑关系,要比去记忆相关的数学公式更重要。
离散变量的概率分布
两点分布
客观世界中最简单的随机事件,可用伯努利试验(Bernoulli trial)来刻画。伯努利试验指的是在同样条件下可重复、且相互独立的一种随机试验,特点是试验只有两种可能的结果:发生或者不发生。掷硬币是伯努利试验的一个典型的例子,一次掷硬币事件,出现的结果要么正面向上,要么反面向上。如果用数学的语言来表达,即 $$ P(X=k)=p^k(1-p)^{1-k}, \, k=0,1 $$ 其中,我们约定$X=1$表示正面向上的结果,发生的概率为$p$。因为结果只有对立的两种,所以这种随机变量的概率分布被称为两点分布,又称伯努利分布或零一分布。从发光二极管的一闪一灭,到手性分子的一左一右,再到大道自然的一阴一阳,可以用$0$或$1$抽象表达的事物无处不在。因此,理解随机变量的概率分布应当从理解伯努利试验开始,从两点分布开始。
二项分布
伯努利试验的核心是可重复,且重复试验之间相互独立。假如某伯努利试验中事件发生的概率$p=\frac{1}{2}$,现在将该试验进行两次,且我们关心的是正面向上的次数,结果仍用变量$X$表示,可能的取值包括${0,1,2}$,分别表示发生$0$次、$1$次和$2$次。不难算出取三个值的概率分别为$\frac{1}{4}$、$\frac{2}{4}$和$\frac{1}{4}$。也就是说两次伯努利试验共有$4$种不同的结果,其中有$2$种结果(“正面-反面”和“反面-正面”)的事件发生次数均为$1$,另外两种分别对应于正面向上次数为$0$和$2$。假如再多重复一次试验,事件发生次数$X \in {0,1,2,3}$,取值的概率为$\frac{1}{8}$,$\frac{3}{8}$,$\frac{3}{8}$和$\frac{1}{8}$。进行三次伯努利试验,其中的规律已经初步显现,相应概率中的分子部分就是二项式展开后的系数,而分母则为三次试验所有可能出现的结果数。所以推广至$n$次伯努利试验的情形,事件发生的次数为$k$的概率可表示为 $$ P(X = k) = C_{n}^{k} p^k (1-p)^{n-k}, \, k = 0,1,2,...,n $$ 。由于$n$次试验中,发生$k$次的情况数由二项式系数$C_n^k$决定,所以$n$重伯努利试验中事件发生的概率分布,称为二项分布,记作$Binomial(n,p)$。二项分布中有两个参数,分别是试验次数$n$和事件发生的概率$p$;变量$X$的数学期望$E(X)=np$,方差$Var(X)=np(1-p)$。
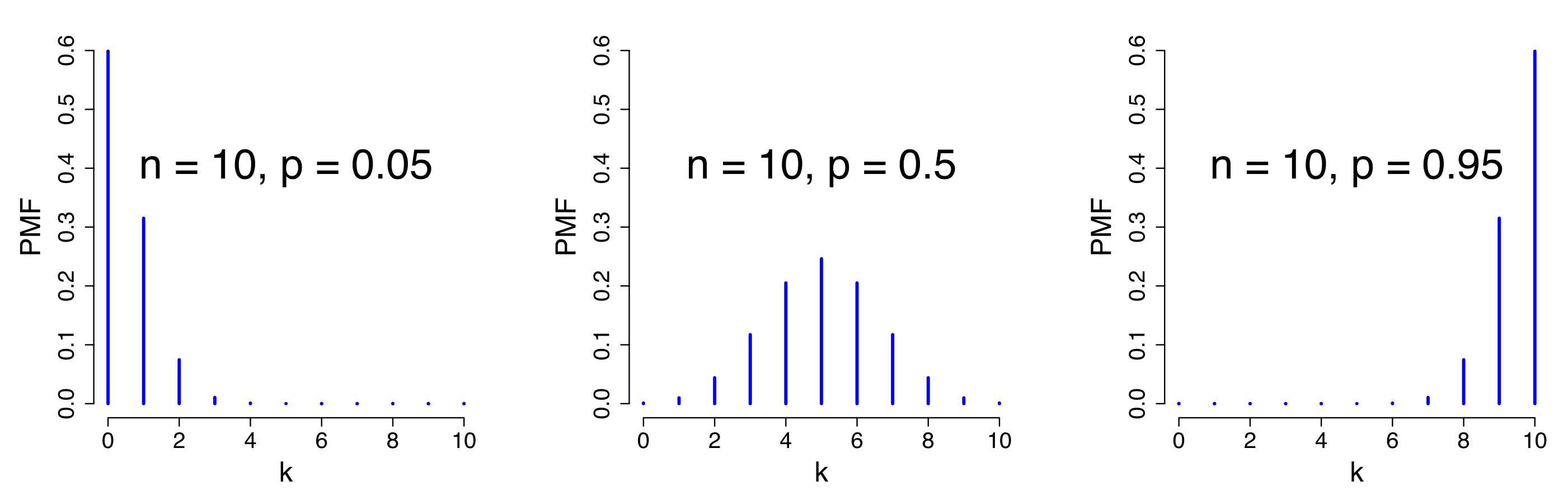
当试验次数$n=100$,事件发生的概率$p=0.5$时,$X$的期望为$50$,即事件平均发生$50$次。但是,对于一次$100$重伯努利试验,事件发生的次数是会发生变化的,可能是$49$次(概率等于$0.078$),也可能是$55$次(概率等于$0.048$),甚至可能是$0$次,虽然概率极低,要知道即使是最有可能的50次,其概率也只有$0.08$。所以事件平均发生$50$次的意义在于,将$100$重伯努利试验重复执行很多次,事件发生次数的平均值为$50$,方差为$25$。借此,我们重温一下数学期望的概念:对于一个变量$X$,它的数学期望$E(X)=\sum_{i=0}^{n} x_i p_i$,即每个可能的取值$x_i$乘以取该值的概率$p_i$后求和。所以数学期望的计算其实就是求加权平均数。数学期望是在更长远的时间尺度上或更广泛的空间范围内,随机变量最可能取的值,或上述例子中事件发生最可能的次数。最有可能的结果并不意味着大概率的结果。因此,在一次试验中追求得到平均结果有时候是不现实的。
泊松分布
实践中,随机事件是否发生通常需要在一定时间或空间范围内考虑,比如某个十字路口发生交通事故的次数,经过该路口的每一辆汽车是否发生事故可用两点分布来描述其概率,那么$n$辆车就可用二项分布来描述它们发生事故的概率($n$辆经过该路口的汽车相当于$n$重伯努利试验)。假设经过该路口的汽车数量为$n$,且发生事故平均次数为$\lambda$,那么每辆车发生事故的概率即为$p=\lambda / n$,代入二项分布的概率公式可得: $$ P(X = k) = C_n^k (\frac{\lambda}{n})^k (1-\frac{\lambda}{n})^{n-k}, \, k=0,1,2,... $$ 这里我们再审视一下$p=\lambda / n$,这种关于概率的定义显然是频率学派的,结合大数定律可知,以上二项分布概率公式的成立需要以$n \rightarrow \infty$为条件,所以 $$ P(X = k) = \lim\limits_{n \rightarrow \infty} C_n^k (\frac{\lambda}{n})^k (1-\frac{\lambda}{n})^{n-k},\, k=0,1,2,... $$ 。下面我们来完成一点数学工作。 $$ \begin{aligned} P(X = k) &= \lim_{n ! \rightarrow ! \infty} \frac{n!}{k!(n-k)!} \cdot \frac{\lambda^k}{n^k} \cdot (1-\frac{! \lambda! }{n})^{n-k} \ &= \lambda^k \cdot \lim_{n !\rightarrow !\infty} \frac{n!}{k!(n-k)!n^k} \cdot \lim_{n !\rightarrow !\infty} (1-\frac{\lambda}{n})^{n-k}\ &= \lambda^k \cdot \lim_{n !\rightarrow !\infty} \frac{n(n-1)(n-2)\cdots(n-i)(n-i-1)\cdots\cdot 2\cdot 1}{k!n^k(n-k)!} \cdot \lim_{n! \rightarrow !\infty} (1-\frac{\lambda}{n})^{n-k} \ &= \lambda^k \cdot \lim_{n !\rightarrow !\infty} \frac{n(n-1)(n-2)\cdots(n-i+1)}{k!n^k} \cdot \lim_{n !\rightarrow ! \infty} (1-\frac{\lambda}{n})^{n-k}\ &= \lambda^k \cdot \frac{1}{k!} \cdot \frac{\lim_{n !\rightarrow! \infty} (1-\frac{\lambda}{n})^{n}}{\lim_{n !\rightarrow !\infty} (1-\frac{\lambda}{n})^{k}} \ &= \lambda^k \cdot \frac{1}{k!} \cdot \lim_{n !\rightarrow !\infty} (1-\frac{\lambda}{n})^{n} \ &= \lambda^k \cdot \frac{1}{k!} \cdot ! e^{-\lambda} \ &= !e^{-!\lambda}\frac{\lambda^k}{k!}, \, k = 0,1,2,... \end{aligned} $$ 最后推导所得公式也就是泊松分布(记作$Poisson(\lambda)$)的概率公式,略去中间推导的过程,有 $$ P(X=k) = e^{-\lambda} \frac{\lambda^k}{k!}, \, k=0,1,2,... $$
。该公式中仅有一个参数$\lambda$,且服从泊松分布的随机变量$X$的期望$E(X)$和方差$Var(X)$同为$\lambda$。
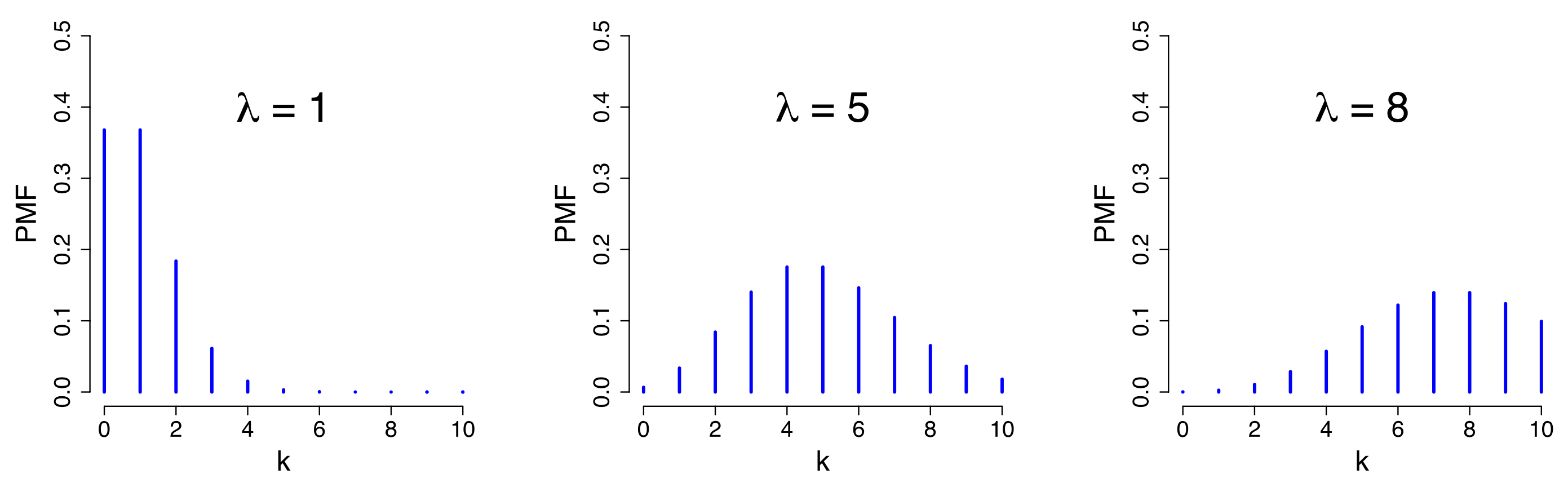
回到那个我们关心的十字路口,$\lambda$是发生在该路口事故的平均次数,与单辆汽车发生事故的概率$p$有关,也与经过该路口的车辆总数$n$有关。抛开驾驶者的人为因素,假设所有驾驶者都有同等水平的驾驶技术和应变能力,那么每辆汽车都有一个相同的发生事故的基础概率$p^\prime$,这个基础概率是综合所有道路和路况估计出来的。然而,对于某一个路口来说,由于道路基础条件和交通管理设施的不同,会在发生事故的概率上有一个该路口特异的事故概率$p_s^{\prime}$。进一步结合经过该路口的汽车总数,那么该路口就有一个特异的事故发生平均次数$\lambda_s$。显然通过对$\lambda_s$的估算和比较,可以帮助我们改进道路交通管理的水平,降低事故发生率。
从泊松分布概率公式的推导过程可以看出,泊松分布和二项分布有着内在的联系。泊松分布实际上描述的是限制在一个空间或时间内进行的$n$重伯努利试验。如何理解这种限制呢?从数学关系上,二项分布到泊松分布,仅要求$n \rightarrow \infty$,但这一条件并不惟一的导致二项分布变成泊松分布,下面我们还会讲到$n \rightarrow \infty$也是二项分布趋于正态分布的条件。这里的重点是存在$\lambda = np$这项限制,所以当$n$非常大时,$p$往往很小。这种$n$很大而$p$很小的情况,放到现实世界里,恰恰是通过一个十字路口发生的交通事故,或者一个细菌培养皿上某细菌的菌落数的真实写照。因此当$n$很大而$p$很小时,二项分布和泊松分布是等价的,只是相对于二项分布,泊松分布的公式更便于计算。
几何分布与负二项分布
$n$重伯努利试验中,如果对事件发生的时机进行限制,会得到不同的概率分布,包括几何分布和负二项分布。几何分布描述的是,在$n$重伯努利试验中,试验经历$k$次失败才第一次成功的概率。换句话说,试验的前$k$次事件都不发生,而第$k+1$次才第一次发生。几何分布有概率公式 $$ P(X = k) = (1-p)^{k} \cdot p, \, k=0,1,2,... $$ ,期望$E(X)=\frac{1}{p}$和方差$Var(X)=\frac{1-p}{p^2}$,记作$GE(p)$。
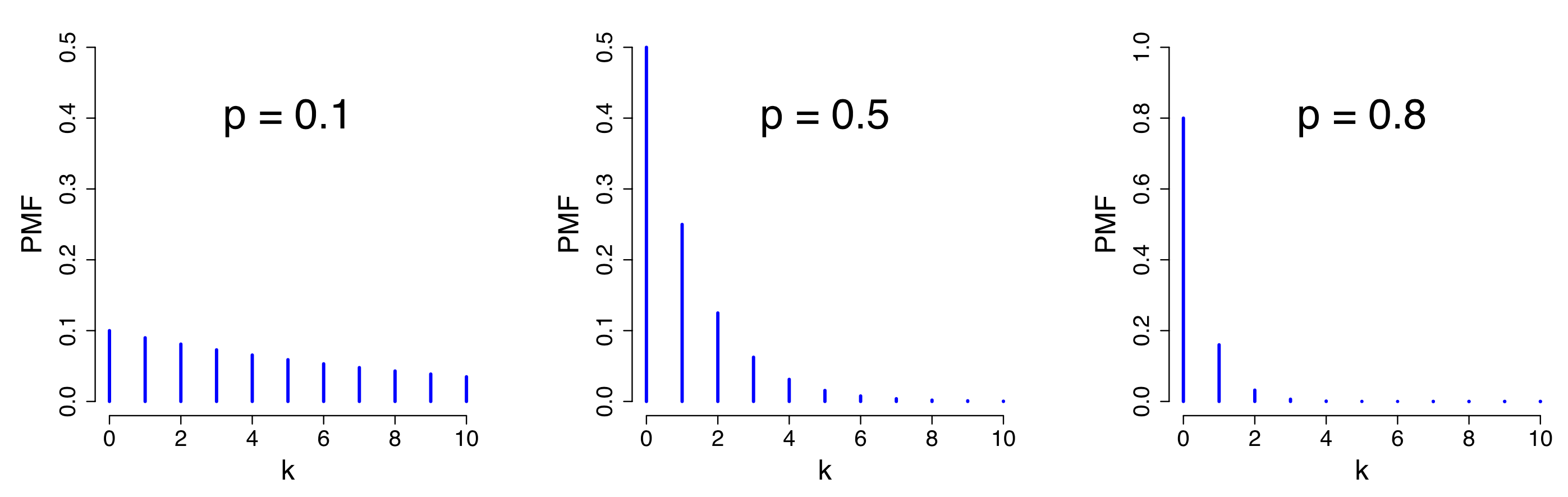
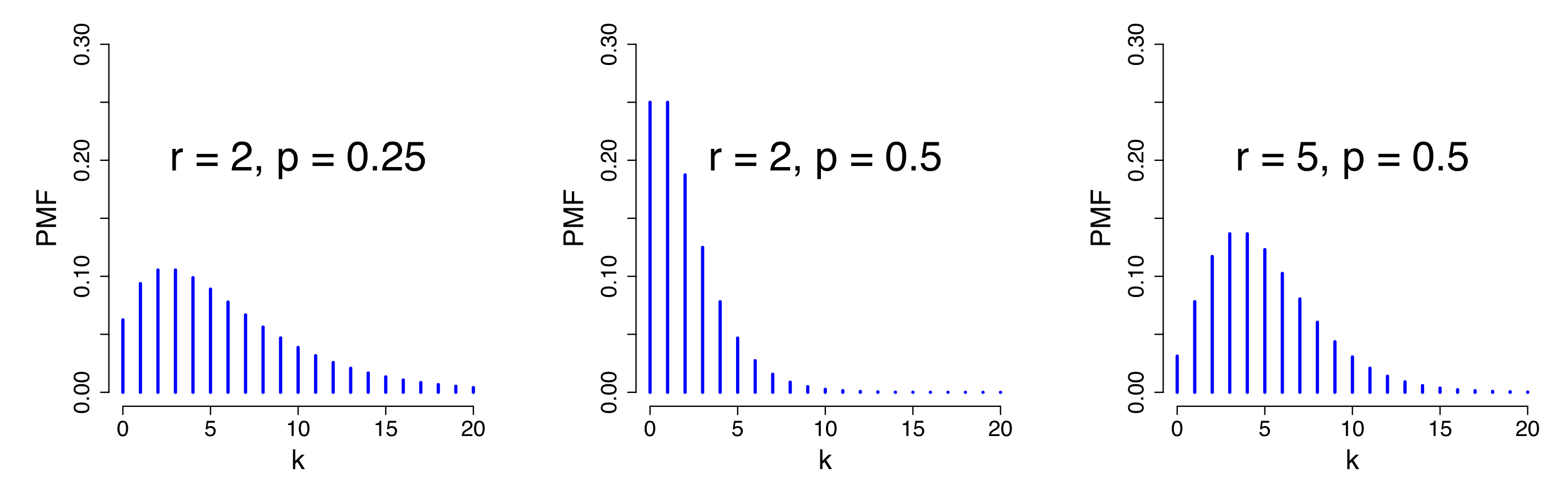
我们可以将几何分布理解为,进行伯努利试验直到事件第一次发生的概率分布。沿着这个逻辑,如果我们感兴趣的是:在$n$重伯努利试验中,试验$k$次才得到第$r$次的事件发生概率(即第$k$次试验观察到第$r$次事件的发生),那么该随机事件(变量)的概率就变成了负二项分布,又称帕斯卡分布。负二项分布有概率公式 $$ P(X=k) = C_{k-1}^{r-1} \cdot p^{r} \cdot (1-p)^{k-r}, \, k=r,r+1,... $$ ,其中包含两个参数$r$和$p$,且期望$E(X)=\frac{r}{p}$和方差$Var(X)=\frac{r(1-p)}{p^2}$,记作$Pascal(r,p)$。这里试验进行了$k$次,最后一次时事件发生了第$r$次,也就是说,前$r-1$次是发生在前$k-1$次试验中的,且前$r-1$次在何时发生是无关紧要的,所以需要乘上二项式系数$C_{k-1}^{r-1}$。在负二项分布的公式中如果令$r=1$,则又回到了几何分布的形式。
几何分布有一个重要的特征,即无记忆性。所谓无记忆性,也就是说进行了$n$次试验没有成功,再进行$m$次试验同样没有成功的概率($P(X > m+n | X > n)$),等于从一开始进行$m$次试验没有成功的概率($P(X > m)$)。也就是说,之前$n$次试验的失败,不会使第$n+1$次及其之后试验成功的概率增加。证明几何分布的无记忆性,可以用条件概率公式,作如下推导: $$ \begin{aligned} P(X > m+n |X > n) &= \frac{P(X > m + n) ! \cap ! P(X > n)}{P(X > n)} = \frac{P(X > m + n)}{P(X > n)}\ &= \frac{\sum_{k=m+n+1}^{\infty}{P (X = k)}}{\sum_{k=n+1}^{\infty}{P (X = k)}} \ &= \frac{\sum_{k=m+n+1}^{\infty}{p(1-p)^{k-1}}}{\sum_{k=n+1}^{\infty}{p(1-p)^{k-1}}} \ &= \frac{(1-p)^{m+n} + (1-p)^{m+n+1} + ...}{(1-p)^n + (1-p)^{n+1} + ...} \end{aligned} $$ 。根据等比数列求和公式,得 $$ \frac{(1-p)^{m+n} + (1-p)^{m+n+1} + ...}{(1-p)^n + (1-p)^{n+1} + ...} = \frac{\frac{(1-p)^{m+n}(1-(1-p)^\infty)}{1-(1-p)}}{\frac{(1-p)^n(1-(1-p)^\infty)}{1-(1-p)}} =(1-p)^m $$ 同理可得$P(X > m) = (1-p)^m$,所以$P(X > m+n | X > n) = P(X > m)$。
与几何分布的无记忆性相关的有一种称为“赌徒谬误”的,不合逻辑的推理方式。赌徒谬误(Gambler's Fallacy)又称为蒙地卡罗谬误,以为在一系列随机发生的事件中,一个事件发生的几率与之前发生的事件有关,也就是说某事件发生的概率会随着之前没有发生该事件的次数增多而上升。如重复抛一个公平硬币,而连续多次抛出反面向上,赌徒们可能错误地认为,下一次抛出正面的几率会较大。与赌徒谬误相反的思想被称为热手谬误,认为连续多次反面向上,下次还是反面的几率较大,这也是错误的。赌徒谬误和热手谬误都都忽视了随机试验间的独立性。
超几何分布与负超几何分布
超几何分布描述了从有限的$N$个物件(其中包含$M$个指定种类的物件)中不放回地抽出$n$个物件,成功抽出该指定种类的物件的次数概率。之所以称为超几何分布(记作$H(M,N,n)$),是因为其形式与超几何函数的级数展式系数有关。 $$ P(X=k) = \frac{C_M^k !\cdot! C_{N-M}^{n-k}}{C_N^n}, \, k=max(0, M+n-N),...,min(n,M) $$ 超几何分布的模型描述的是不放回地抽样过程,有三个参数$M,N,n$,期望$E(X) = \frac{nM}{N}$,方差$Var(X)=\frac{nM}{N}(1-\frac{M}{N})\frac{N-n}{N-1}$。在超几何分布中,当$N !\rightarrow ! +\infty$时,$\frac{M}{N} ! \rightarrow ! p$,这里的概率$p$表示的是指定种类物件出现的概率,进而有超几何分布的期望$E(x)=np$,方差$Var(x)=np(1-p)$ ,恰为二项分布的期望与方差。所以$N \rightarrow +\infty$时,超几何分布近似为二项分布。
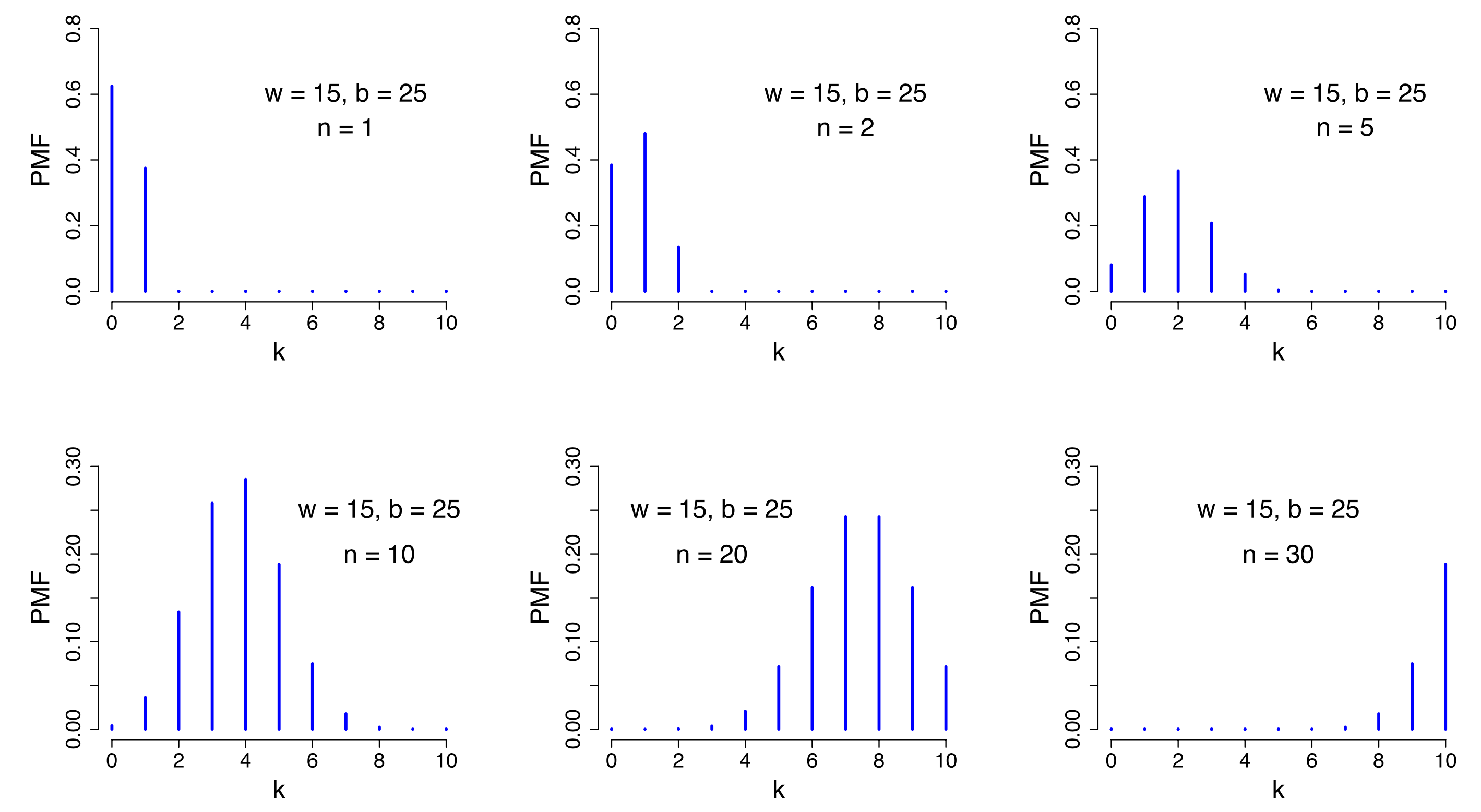
与几何分布与负几何分布的关系类似,如果从有限的$N$个物件总体中接连进行不放回地抽样,直到指定种类的的物件(共$M$个)恰好抽出$r$个为止,所需抽样次数$X$服从负超几何分布,概率公式为 $$ P(X=k) = \frac{C_{k-1}^{r-1} !\cdot ! C_{N-k}^{M-r}}{C_N^M}, \, k=r,r+1,...,r+n-M, (r ! \leq ! M ! \leq ! N) $$
,有数学期望$E(X) = \frac{r(N+1)}{M+1}$和方差$Var(X) = \frac{r(N+1)(N-m)(M-r+1)}{(M+1)^2(M+2)}$,记作$NH(r,M,N)$。
齐夫分布与齐塔分布
1949年美国语言学家乔治·金斯利·齐夫 (George Kingsley Zipf) 研究英文单词的出现频率时,发现如果把单词频率从高到低的次序排列,每个单词出现频率和它的符号访问排名存在简单反比关系$P(r)=Cr^{-1}$,其中$r$表示一个单词的出现频率的排名,$P(r)$表示排名为$r$的单词的出现频率。也就是说,频率最高的单词出现的频率大约是出现频率第二位的单词的2倍,而出现频率第二位的单词则是出现频率第四位的单词的2倍。这一统计规律在很多领域中都是适用的,如人们的收入,互联网的网站数量和访问比例,和固体破碎时碎片大小等等,因此该规律被称为齐夫定律。齐夫定律是一个实验定律,而非理论定律。如果把排名和频率分别做对数转换,表示在散点图上,如果所有的点接近一条直线,那么它就遵循齐夫定律。
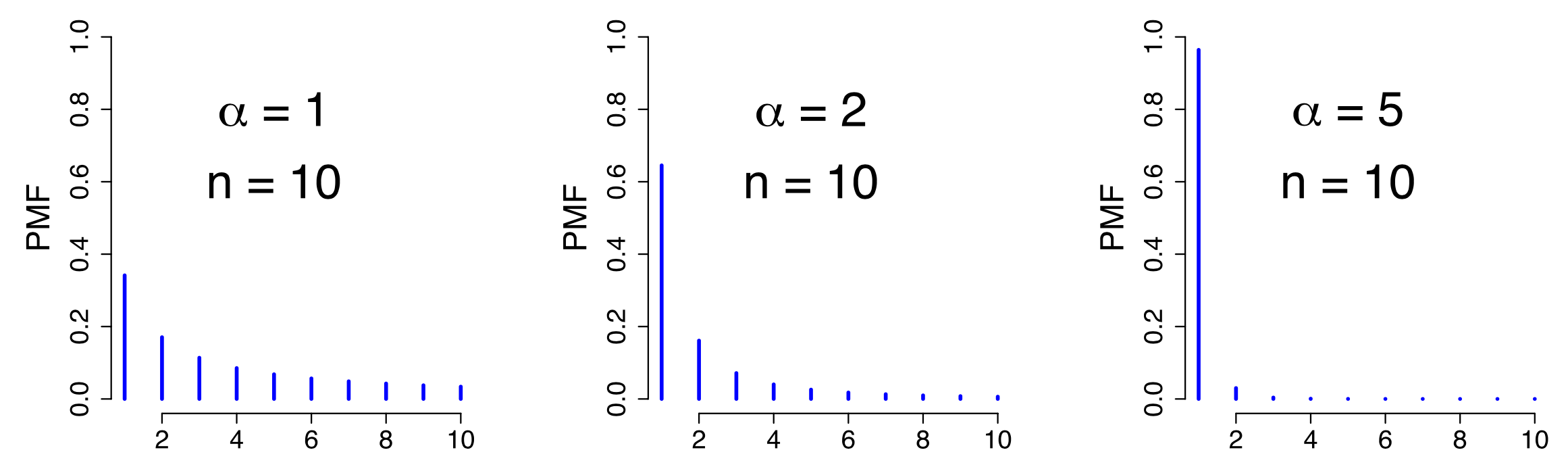
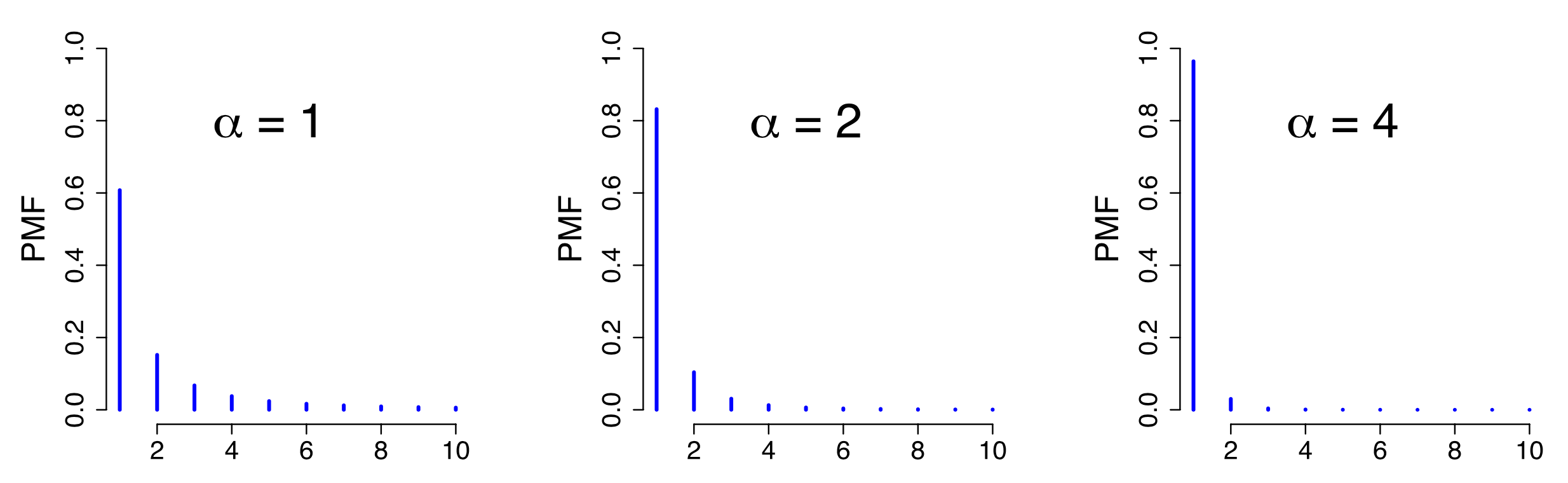
齐夫定律在统计学上的表现形式,即齐夫分布,其概率公式为 $$ P(X = k) = \frac{1}{k^\alpha \sum_{i=1}^n i^{-\alpha}},\, k=1,2,...,n; \alpha \geq 0 $$
,其中参数$\alpha$决定了分布的形状,参数$n$表示变量取值的个数;有数学期望$E(X) = \frac{H_{n,\alpha-1}}{H_{n,\alpha}}$和方差$Var(X) = \frac{H_{n,\alpha-2}H_{n,\alpha}-H_{n,\alpha-1}^2}{H_{n,\alpha}^2}$,其中$H_{n,\alpha} = \sum_{i=0}^{n} i^{-\alpha }$。齐夫分布当$n \rightarrow \infty$时,就变为了齐塔分布,概率公式为 $$ P(X = k) = \frac{1}{k^\alpha! \sum_{i=1}^\infty! i^{-\alpha!}},\, k=1,2,...; \alpha \geq 0 $$ 。在齐塔分布中与齐夫分布$H_{n,\alpha}$函数相对应的函数,称为黎曼$\zeta$函数$\zeta(\alpha) = \sum_{i=0}^{\infty} i^{-\alpha}$。
离散均匀分布
假设离散型随机变量$X$在整数区间$[a,b]$内取值,且每个取值的概率相同,则$X$服从离散均匀分布,又称矩形分布,有概率公式 $$ P(X) = \frac{1}{b-a+1}, \, X=a,a+1,...,b $$
利用服从离散均匀分布的随机数生成(R语言rdunif {purrr}),可用来模拟抛硬币和掷骰子之类的试验。